Project Database Unique IDs (PDUIDs) are stored for each item of each type and are unique across all Cradle projects. The PDUID assists in the configuration control and change tracking of information in the Cradle database. The PDUID uniquely identifies every relevant item in all Cradle databases.
This newsletter contains a mixture of news and technical information about us, and our requirements management and systems engineering tool “Cradle”. We would especially like to welcome everyone who has purchased Cradle in the past month and those who are currently evaluating Cradle for their projects and processes.
We hope that 3SL and Cradle can deliver real and measurable benefits that help you to improve the information flow within, the quality and timeliness of, and the traceability, compliance and governance for, all of your current and future projects.
If you have any questions about your use of Cradle, please do not hesitate to contact 3SL Support.
Controlling PDUIDs in Import and Export
The primary method of moving data into or out of Cradle databases is import/export. Regardless of the form of the data files used, there are some basic characteristics of import operations that affect the handling of PDUIDs and which can be controlled by the user when importing. These choices can be saved with other import options in an import format file. Such formats can be used for later imports, and specified for command-line based imports using the c_io utility. Using import format files is recommended as it ensures consistency between imports.
Further Details
For further details on this part 4 of a description of PDUIDs, please see the full blog entry here.
Latest Updates
The latest technical and related topics in our blog are:
Follow these links to see the latest blog updates and then use the blog’s search to find other topics of interest! With over 500 posts in the blog, we are sure that you will find lots to interest you in the details of Cradle and 3SL!
We would also like to thank all attendees on our Document Publisher course which we provided in September.
Halloween
Halloween is a celebration observed in many countries on 31st October, the eve of the Western Christian feast of All Saints’ Day. It begins the observance of Allhallowtide, the time in the liturgical year dedicated to remembering the dead, including saints (hallows), martyrs, and all the faithful departed.
Spirits, Cauldrons, Witches and Jack-O-Lanterns
Cauldron
The masses were hungry, they needed a solution. The Requirements Master toiled over her cauldron. Into the mix she added a freshly cut bunch of requirements, a handful of ideas and a sackful of luck. The brew steamed for day and night, and as members of her family walked by they threw in their ha’p’orth of comments.
The requirements soon stewed and disintegrated, but all could see the ideas floating to the top.
The swirling liquor produced a heady vapour, caught by the nostrils of the management team. They liked what they smelled and believed the Requirements Master was doing just fine.
When the soup was dished up to the masses, the flavour was odd, and it didn’t satisfy their hunger. They felt weakened and sad, some even passed over to another project. “A curse has been placed upon this town”, they cried, “the Requirements Master is a Witch!” The town’s folk lit lanterns to guide the lost souls home to the land of abandoned engineering.
Well, that’s certainly one way to do design and engineering! Whilst it is often the case that many ideas are ‘thrown into the melting pot’, it should be used as a tool elicit idea, and not to ‘hopefully solve’ the problem. A more complex mix isn’t necessarily successful. As the tale told, losing sight of the requirements is a dangerous thing. Managing the project by a whiff of success is unlikely to be accurate.
So, don’t fall under the spell of those that don’t know how to engineer, and let Cradle light your way!
Social Media
Congratulated @hensoldt on donating €6,000 to the children’s intensive #care program #Bärenfamilie.
We also congratulated @WeAreHII after the first Flight III Arleigh Burke class guided missile destroyer Jack H Lucas departed HII’s Ingalls Shipbuilding division
This is the fourth and last in a short series of posts that explain Project Database Unique IDs (PDUIDs). This post explains how PDUIDs can be controlled when importing information into Cradle.
Exchanging Information
The primary method of moving data into or out of Cradle databases is import/export. Regardless of the form of the data files used, there are some basic characteristics of import operations that affect the handling of PDUIDs and which can be controlled by the user when importing. These choices can be saved with other import options in an import format file. Such formats can be used for later imports, and specified for command-line based imports using the c_io utility. Using import format files is recommended as it ensures consistency between imports.
Default Behaviour
When importing information:
Every item imported will have a PDUID when it is saved, even if the import data does not contain a PDUID
The DID in the PDUID of all imported items will be set to the DID of the current Cradle system. For data that is being loaded from other Cradle systems, this means that the PDUIDs of the items in the original and imported databases will always be different. Even if their PUIDs are the same, their DIDs will be different.
If an item being imported does not exist in the PDUID lookup table, then a new entry will be created in the table for the item. This new entry will have a PDUID. This PDUID will either be newly generated (the default), or if the import data contains a PDUID and the user has chosen to force the import of PDUIDs, then the PDUID from the import data will be used.
If an item being imported exists in the PDUID lookup table and its table entry is marked deleted, then this table entry will be reinstated. If the user has specified to use the PDUID from the import file, the PDUID in the table entry will be replaced with the PDUID from the import file, else the table entry will be reinstated and the imported item will have the original PDUID from the lookup table.
If an item being imported has a PDUID that is already used for a different item in the database, then the PDUID in the import file will not be used and the imported item’s PDUID will be replaced, regardless of any import options to the contrary
All instances of an item have the same PDUID. Therefore, the PDUID of an item in the database will only be changed if all instances of the item can be changed. If there is any reason why all instances of an item cannot have their PDUIDs changed, then none of the instances will have their PDUIDs changed. As an example, if a user tries to import items with Overwrite set On and wants the PDUIDs in the import file to be used in the database, then the user must have RW access to all instances of the item in the database and the import data must update all of these instances.
Force Use of Existing PDUIDs
When importing data, you can choose to ignore any PDUIDs in the import/export file and instead keep the PDUIDs already in the database. To do this, de-select the checkbox Import PDUIDs from file (do not generate them)
This means that:
If an item in the import data does not contain a PDUID, a PDUID will be generated for it as it is imported
If an item in the import data does not exist in the database, then PDUIDs will be generated for them
If the item in the import data does exist in the database, then the items will still have their original PDUIDs after the import and any PDUIDs in the import data will be ignored
Force Use of Import File PDUIDs
When importing data, you can choose to use PDUIDs in the import/export file and replace the PDUIDs already in the database. To do this, select the checkbox Import PDUIDs from file (do not generate them)
This means that:
If the item in the import data does not contain PDUIDs, then PDUIDs will be generated for items as they are imported
If the item in the import data does not exist in the database, then the PDUID in the import data will be used provided that it does not already exist in the PDUID lookup table and if it does exist in the table then if that table entry is active then a PDUID will be generated and if the table entry is not active then the PDUID in the import data will be used and the table entry will be replaced
If the item in the import data does exist in the database, then:
If the PDUID in the import data does not already exist in the PDUID lookup table then:
The PDUID in the import data will be used
Else if the lookup table entry is active then:
If the lookup table entry is for a different item then:
A PDUID will be generated and the PDUID in the import data will not be used
Else if the user has RW access to all instances of the item and all instances of the item are to be updated by the import then:
The PDUID in the import data will be used
Else
The PDUID already in the lookup table entry and the database items will not be changed
Else the lookup table entry is inactive so:
The PDUID in the import data will be used
Force PID Change
Whenever an item in an import file is to be imported as a new item in a database (not overwriting an existing item) then the PDUID for that new item will either come from the import data (if it contains PDUIDs) or a new PDUID will be generated. The PID in such PDUIDs will be either PID of the current database, or you can force a specific PID.
This can be useful if, you want to distinguish the data being imported with a specific PID, but the import data does not have that PID. For example, if you are importing into a single database data from multiple other databases then you might want to force the PIDs in the PDUIDs of items imported from database “A” to have one value and for the PIDs in the PDUIDs of items imported from database “B” to have a different value.
If you did this then, for instance, the PDUID facilities in queries could be used to distinguish between these sets of imported data.
Welcome to the September 2023 newsletter from 3SL!
This newsletter contains a mixture of news and technical information about us, and our requirements management and systems engineering tool “Cradle”. We would especially like to welcome everyone who has purchased Cradle in the past month and those who are currently evaluating Cradle for their projects and processes.
We hope that 3SL and Cradle can deliver real and measurable benefits that help you to improve the information flow within, the quality and timeliness of, and the traceability, compliance and governance for, all of your current and future projects.
If you have any questions about your use of Cradle, please do not hesitate to contact 3SL Support.
Latest Updates
The latest technical and related topics in our blog are:
Follow these links to see the latest blog updates and then use the blog’s search to find other topics of interest! With over 500 posts in the blog, we are sure that you will find lots to interest you in the details of Cradle and 3SL!
We would also like to thank all attendees on the Requirements Management course that we held in August.
Using PDUIDs
This section explains how PDUIDs can be used in Cradle.
Opening Items
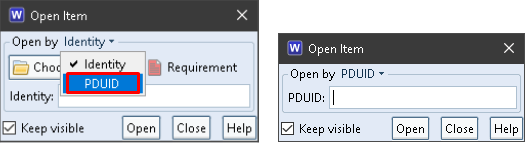
You can open an item by simply specifying its PDUID. You do not need to specify the type of the item using the Item Type Chooser dialogs in the WorkBench and web UIs. For items in models, you do not need to choose the correct domain and then locate the model inside that domain.
You simply specify the PDUID:
Open Item by PDUID
The latest instance of the item will be opened.
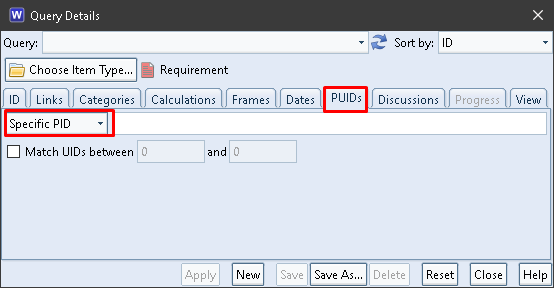
Queries
You can find items based on their PDUIDs, or components of the PDUIDs, in addition to any other criteria that you may have set inside the query. Select the PUIDs tab in the Query Details dialog:
PDUIDs in Queries
The selection of items by PDUID will return all instances that you can access RO or RW.
Further Details
For further details on this description of PDUIDs, please see the full blog entry here.
Testimonial
Our Support Team received a wonderful testimonial from one of our customers:
“The support team does an amazing job. Is the better support I ever have in a Software. It was very important decision factor to use CRADLE in the company. “
We try to deliver unrivalled service to all of our customers. If you have been especially pleased, or disappointed, with our support, then let us know!
#Cytovale announced they have partnered with a leading health system (Franciscan Missionaries of Our Lady Health System) to improve sepsis care for their patients
This is the third in a short series of posts that explain Project Database Unique IDs (PDUIDs). This post explains how PDUIDs can be used in Cradle. The next and final post in the series will explain how PDUIDs can be controlled when information is moved between databases.
Opening Items
You can open an item by simply specifying its PDUID. You do not need to specify the type of the item using the Item Type Chooser dialogs in the WorkBench and web UIs. For items in models, you do not need to choose the correct domain and then locate the model inside that domain.
You simply specify the PDUID:
Open Item by PDUID
The latest instance of the item will be opened.
Queries
You can find items based on their PDUIDs, or components of the PDUIDs, in addition to any other criteria that you may have set inside the query. Select the PUIDs tab in the Query Details dialog:
PDUIDs in Queries
The selection of items by PDUID will return all instances that you can access RO or RW.
Specific PID
If you choose Specific PID then you can enter a PID and an optional UID range. If you only enter a PID, then the query will return all items whose PDUIDs contain that PID. This could be useful if you have been importing data from other databases and so the items in your database have PDUIDs with different PIDs.
For example, if you have separate databases that have different PIDs for:
Different missions in a programme, or
Different vessels in a class of vessels
and you have combined the data from several of these databases into one database, then this option will allow you to find only the items with a single PID, such as for a single mission or for a single vessel. You can optionally filter the items further by specifying a UID range. You can omit the leading zeroes from the UIDs.
Specific PUID
If you choose Specific PUID then you can enter a PUID (the PID and UID) and the query will return all instances of the item with that specific PUID that you can access RO or RW and subject to the other constraints in the query (such as returning only the latest instance that you may have specified in the ID tab).
PUID From
If you choose PUID from then you can enter a PUID (the PID and UID) and the query will return all instances of all items whose PUIDs are greater than the value you specified which will be the combination of:
All items with the same PID and whose UIDs are greater than your specified value
All items with PIDs greater than your specified value and any UID
that you can access RO or RW and subject to the other constraints in the query (such as returning only the latest instance that you may have set in the ID tab).
Referencing Data in Other Items
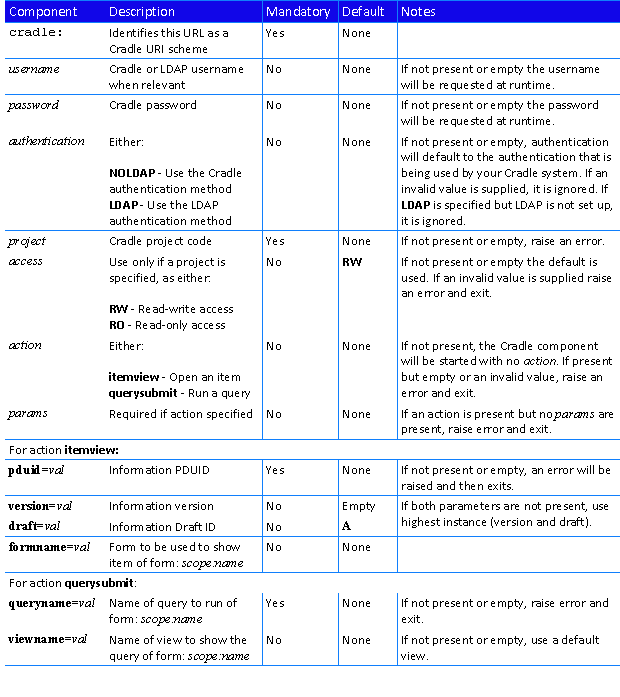
Items in a Cradle database can hold their information in any number of frames. Each frame is of a user-defined frame type that defines the characteristics of the frame. The data in frames of a frame type is normally stored in the Cradle database, but this can be controlled by the storage mechanism of the frame’s frame type:
In PDB
:
The frame’s data is stored in the Cradle database
As File
:
The frame’s data is stored in an external file whose pathname, size, last access and modified times are stored in the Cradle database
By Command
:
The frame’s data is held in an external environment under an identity, the database stores this identity, and uses Get and Set commands in the frame type to move the data between the environment (specified by the $IDENTITYCommand Directive) and a temporary file (specified by the $PATH Command Directive) where it can be operated on. For example:
This example exports the frame’s contents and sends to the application supplied in the frame type’s View or Edit command and saves the contents from the application back into the frame.
As Reference
:
The frame’s data is stored at a location outside Cradle and the frame stores this external location (such as a pathname or a URL). The data’s location is given to the frame type’s View command, which does not wait for this processing to complete – unlike in the other storage mechanisms.
Referenced File From Item
:
The frame’s data is held in a frame of a different item. The frame stores the PDUID of the other item whose data is being referenced (latest instance), and the name of the frame in this other item that contains the data. When the frame is accessed via a View command, Cradle opens the other item using its PDUID and copies the data from the referenced frame into a temporary file. This mechanism allows data in one item to reference data in another item, sharing the data between them.
Cradle URLs
Cradle URLs are URLs that can start a Cradle WorkBench client and either open an item or run a query. The action specified in a Cradle URL is executed by the c_url utility shipped in the Cradle clients. It can be run from a command line, an application, or a web browser that has been told about Cradle URLs (an option when Cradle clients are installed).
Cradle URLs are a way for another application to interface to Cradle. The other application can store Cradle URLs as, in effect, pointers to items in the Cradle database. When the user wants to access the Cradle item, the external application can either run c_url on the specified Cradle URL, or route it through a web browser that, in turn, will launch c_url.
Cradle URI Scheme
A URI scheme defines the structure of a URL. The Cradle URI scheme is:
by specifying a Cradle URL with the PDUID and instance details of the item to be opened.
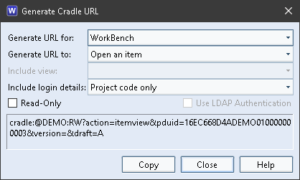
Creating Cradle URLs
Cradle URLs can be created from the Tools tab WorkBench UI or any web UI. Once an item is selected:
Create Cradle URL
The Cradle URL shown in the dialog can be copied and pasted:
Into another application to provide a link to the selected item in Cradle
Into the c_url utility to execute the action in the URL
Into a web browser that understands the Cradle scheme, when it will launch the c_url utility to perform the requested action
API
Cradle has an Application Programming Interface (API) that supports both C/C++ and VB.NET. You can create any number of applications using the API. All of these applications will connect to the CDS in the same way as any non-web-based Cradle client supplied by 3SL (such as WorkBench or Document Publisher). Each of your applications can service one or many users. You need one API/WSI connection licence for every application that you want to concurrently connect to Cradle.
The API contains many routines. Collectively these routines provide facilities to create, read, update and delete both items and the cross references between them. The main data type for items is CAPI_ITEM_T which has components for both item identities and PDUIDs. The main data type for cross references is CAPI_XREF_T which contains the details of the cross reference but not the items that it connects. This is because cross references are not retrieved by themselves, rather the API returns a list of linked items each of which is a structure containing the CAPI_ITEM_T for the linked item and the CAPI_XREF_T for the cross reference by which it is linked. As such, the “from” and “to” items for a cross reference are implicit in the data structures.
A PDUID can be used to open an existing item using CAPI_Item_Open().
WSI
Cradle has a Web Services Interface (WSI) that supports a RESTful message protocol. You can create any number of applications using the WSI. All of these applications will connect to the Cradle Web Server (CWS) in the same way as any web-based Cradle client supplied by 3SL. Each of your applications can service one or many users. You need one API/WSI connection licence for every application that you want to concurrently connect to Cradle. Each of these connections can either be session-based or it can use message-by-message connections.
The WSI contains many operations. Collectively, these operations provide facilities to create, read, update and delete both items and the cross references between items. The data sent and received in these operations is packaged in JSON. These JSON packets contain full details of items and cross references and include both item identities and PDUIDs.
The WSI predominately uses PDUIDs as a means to specify items of information, and for links between items. For example using the curl command to send a HTTP message to a Cradle WSI session whose details are in the file cookies.txt to the CWS running on port 8015 at server myserver to get the contents of a database item into a local JSON file:
curl -X GET -b cookies.txt “http://myserver:8015/rest/projects/DEMO/items/16EC668D4ADEMO010000000907?fields=all” > myItem.json
and to update the same item in Cradle with new information added into the same local JSON file:
curl -X PUT -b cookies.txt “http://myserver:8015/rest/projects/DEMO/items/16EC668D4ADEMO010000000907” -d @myItem.json
This newsletter contains a mixture of news and technical information about us, and our requirements management and systems engineering tool “Cradle”. We would especially like to welcome everyone who has purchased Cradle in the past month and those who are currently evaluating Cradle for their projects and processes.
We hope that 3SL and Cradle can deliver real and measurable benefits that help you to improve the information flow within, the quality and timeliness of, and the traceability, compliance and governance for, all of your current and future projects.
If you have any questions about your use of Cradle, please do not hesitate to contact 3SL Support.
Latest Updates
The latest technical and related topics in our blog are:
Follow these links to see the latest blog updates and then use the blog’s search to find other topics of interest! With over 500 posts in the blog, we are sure that you will find lots to interest you in the details of Cradle and 3SL!
We would also like to thank all attendees on both our Project Administration course and Cradle Introduction course which we provided in July.
Displaying PDUIDs and their Components
Here we explain how to view PDUIDs and their components.
Viewing PDUIDs
You can show PDUIDs and their parts anywhere that you can show any other item attributes, especially in views and forms. Use views to control how the results of queries will be shown. You use forms to show single items. In both cases, you decide which of the items’ attributes to show. You can show either PDUIDs or any of their parts. All of these values will be displayed read-only.
Views
A view specifies which of an item’s attributes will be shown, and the order and position of the values of these attributes.
Display Styles
You can display a view in one of four display styles:
List
:
Lists show each item in a row of read-only text. Lists cannot contain colour, images or linked items. You use a list to show the maximum number of items on screen at the same time.
Table
:
Each item is shown in one or more rows, each of one or more columns, which creates a grid of display cells. Each of these cells can contain text or graphics. You can specify colour and text styles for the cells. The cells also allow linked items to be shown. Some cells are editable. You can also create display menus of user-defined commands. Table style is the most common display style.
Document
:
This is the same as Table style except that row and column borders are not shown and different font sizes are used to display the first row of each item. The size of the text is based on the identity or other alphanumeric attribute, so that the effect is similar to the headings and subheadings of text in a document.
Tree
:
Each item is displayed as a node in a tree and a single row of values similar to List style. You can control the format of the tree nodes by a separate view. These tree nodes can be expanded and collapsed to show or hide sets of linked items.
Views are Tables
Most views have one row of cells, each containing one of the item’s attributes. So if a query returns 200 items, then the view will contain 200 rows, one per item. Items can be shown over more than one row. For example, if the same query is displayed with a view that uses 3 rows to show each item, then the result will be a table with 600 rows of the form:
Items as Table Rows in a View
View Cells
Each cell in a view can contain fixed text, an attribute, linked items, or several attributes combined into a single value with some optional separating characters.
PDUIDs in Views
All of the components of PDUIDs are available to be shown in cells in a view.
Further Details
To continue reading, please see the full blog entry here.
Joscar
We are pleased to announce that following the submission of our renewal, our compliance information has now been published for buying organisations using JOSCAR (the Joint Supply Chain Accreditation Register).
JOSCAR
Social Media
We celebrated #TestimonialTuesday by sharing some of the wonderful feedback received from our customers
This is the second in a short series of posts that explain Project Database Unique IDs (PDUIDs). This post explains how to view PDUIDs and their components. Later posts will explain:
How they can be used in operations in Cradle tools, API and WSI
How PDUIDs can be changed or preserved when information is moved between databases
Viewing PDUIDs
You can show PDUIDs and their parts anywhere that you can show any other item attributes, especially in views and forms. Use views to control how the results of queries will be shown. You use forms to show single items. In both cases, you decide which of the items’ attributes to show. You can show either PDUIDs or any of their parts. All of these values will be displayed read-only.
Views
A view specifies which of an item’s attributes will be shown, and the order and position of the values of these attributes.
Display Styles
You can display a view in one of four display styles:
List
:
Lists show each item in a row of read-only text. Lists cannot contain colour, images or linked items. You use a list to show the maximum number of items on screen at the same time.
Table
:
Each item is shown in one or more rows, each of one or more columns, which creates a grid of display cells. Each of these cells can contain text or graphics. You can specify colour and text styles for the cells. The cells also allow linked items to be shown. Some cells are editable. You can also create display menus of user-defined commands. Table style is the most common display style.
Document
:
This is the same as Table style except that row and column borders are not shown and different font sizes are used to display the first row of each item. The size of the text is based on the identity or other alphanumeric attribute, so that the effect is similar to the headings and subheadings of text in a document.
Tree
:
Each item is displayed as a node in a tree and a single row of values similar to List style. You can control the format of the tree nodes by a separate view. These tree nodes can be expanded and collapsed to show or hide sets of linked items.
Views are Tables
Most views have one row of cells, each containing one of the item’s attributes. So if a query returns 200 items, then the view will contain 200 rows, one per item. Items can be shown over more than one row. For example, if the same query is displayed with a view that uses 3 rows to show each item, then the result will be a table with 600 rows of the form:
Items as Table Rows in a View
View Cells
Each cell in a view can contain fixed text, an attribute, linked items, or several attributes combined into a single value with some optional separating characters.
PDUIDs in Views
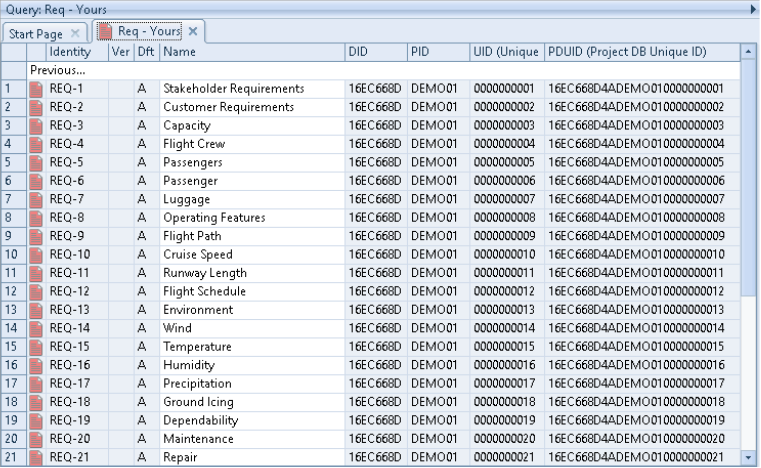
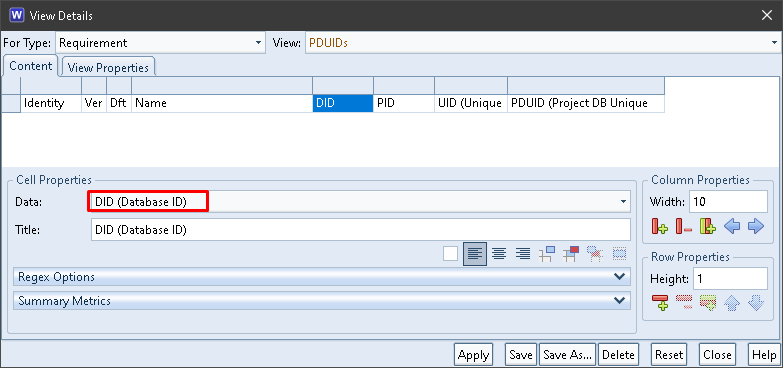
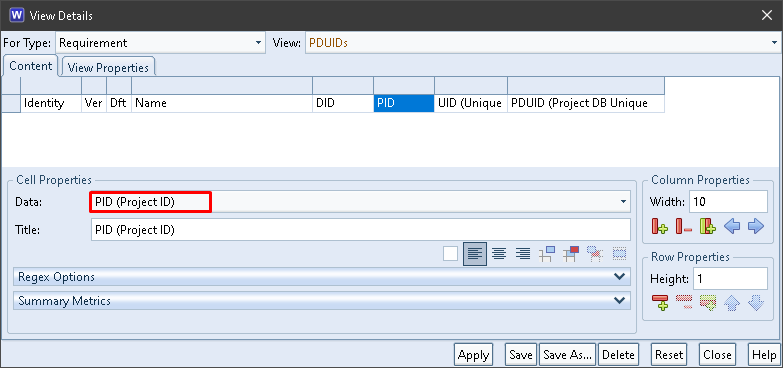
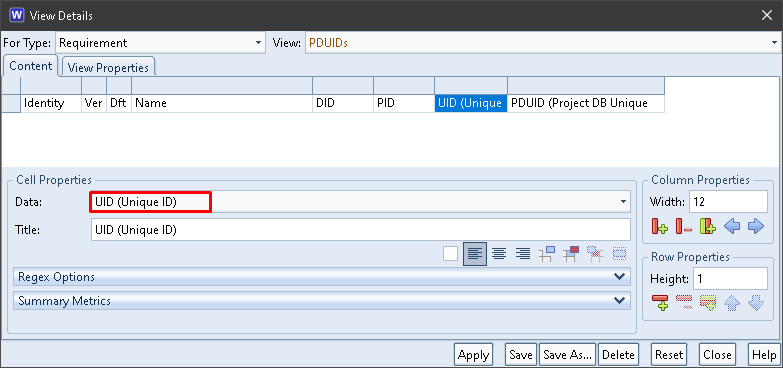
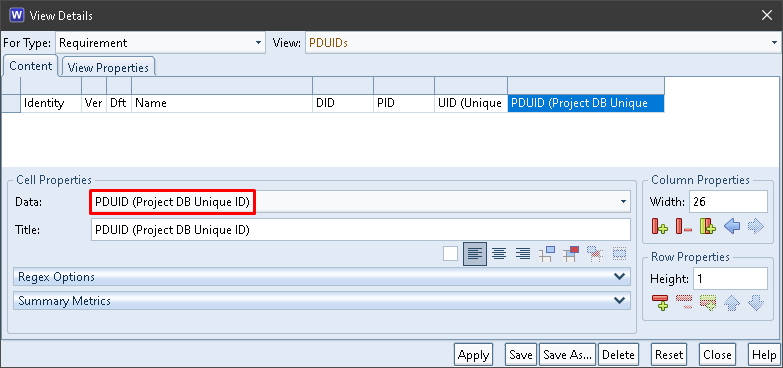
All of the components of PDUIDs are available to be shown in cells in a view. For example:
DID PID UID and PDUID in View in Table Style
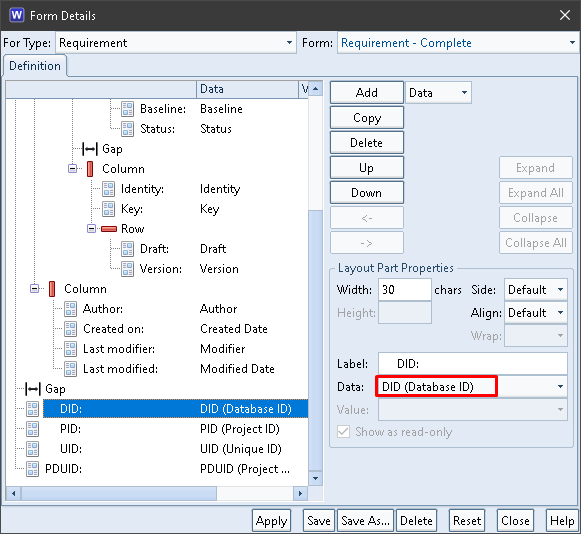
The DID column contains the Database ID component from the items’ PDUIDs:
DID in a View
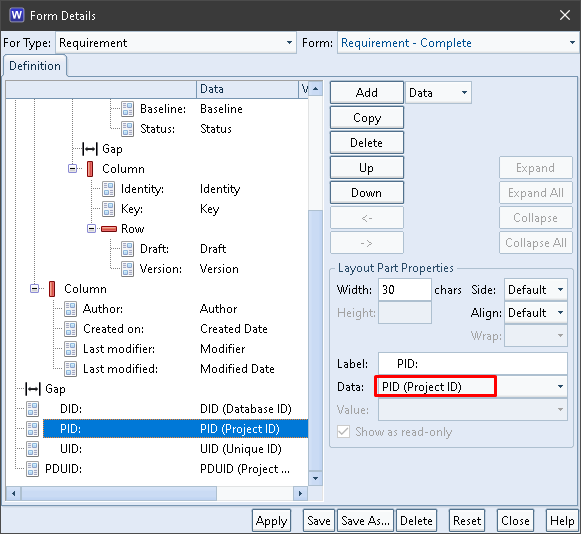
The PID column contains the Project ID component from the items’ PDUIDs:
PID in a View
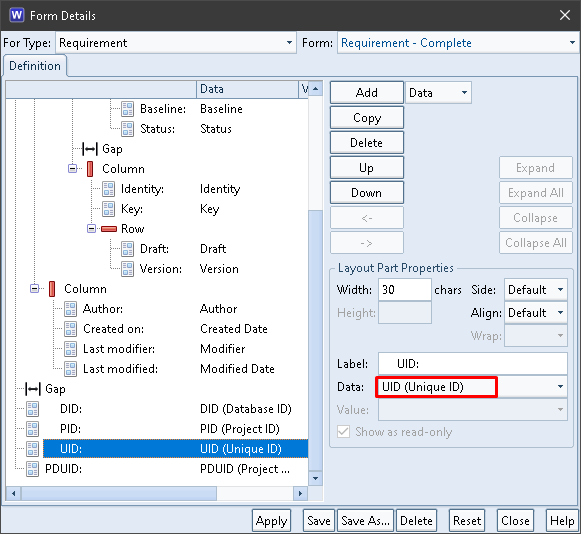
The UID column contains the Unique ID component from the items’ PDUIDs:
UID in a View
The PDUID column contains the items’ entire PDUIDs:
PDUID in a View
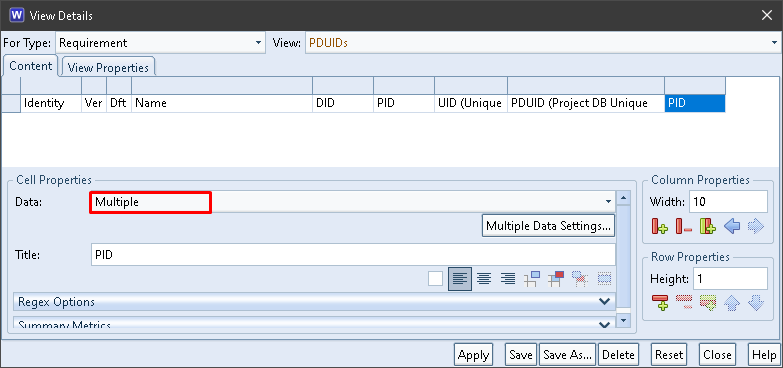
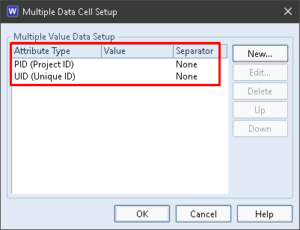
There is no component to show the items’ Project Unique IDs (PUIDs). The PUID is the combination of the PID and UID, so we can easily output this in a view cell using the data type Multiple and concatenating these attributes with no separators:
PUID in a ViewPUID Component Attributes
All of these cells will be read-only in all display styles since PDUIDs are not user-modifiable attributes.
Forms
A form is a collection of fields, grouped into rows and columns, that display information for a single item. You can arrange the fields in a form in any way that you wish, to create any layout of information that you wish. Regions of forms can be made collapsible inside panels. Each field in a form can contain fixed text, an attribute or a collection of linked items. If an attribute is editable, then the form will allow it to be edited, subject to the user’s access rights to the item and that specific attribute. In addition, a field can be set to prevent editing of an attribute that would otherwise be editable.
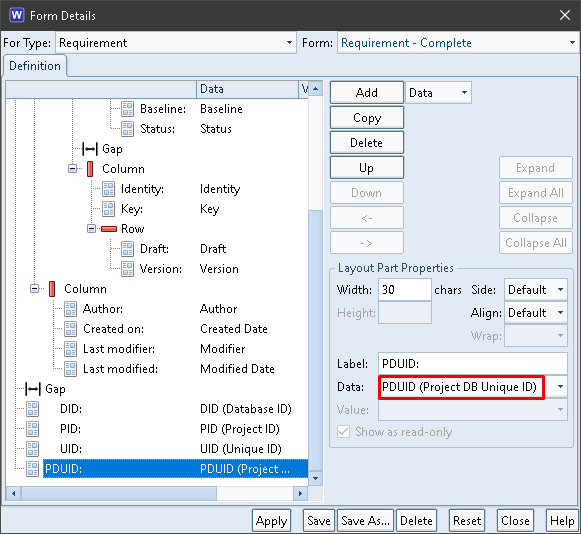
All of the components of PDUIDs are available to be shown in fields in a form. For example:
PDUID and Components in a Form
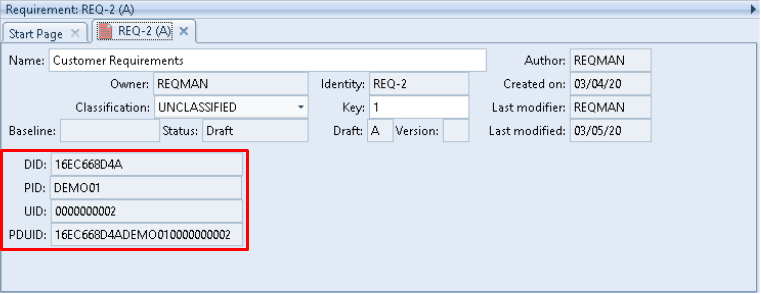
The DID field contains the Database ID component from the item’s PDUID:
DID in a Form
The PID field contains the Project ID component from the item’s PDUID:
PID in a Form
The UID field contains the Unique ID component from the item’s PDUID:
This newsletter contains a mixture of news and technical information about us, and our requirements management and systems engineering tool “Cradle”. We would especially like to welcome everyone who has purchased Cradle in the past month and those who are currently evaluating Cradle for their projects and processes.
We hope that 3SL and Cradle can deliver real and measurable benefits that help you to improve the information flow within, the quality and timeliness of, and the traceability, compliance and governance for, all of your current and future projects.
If you have any questions about your use of Cradle, please do not hesitate to contact 3SL Support.
PDUIDs
When we work with information, we need a way to distinguish each piece of information from all other pieces of information so we can be sure we have found what we were searching for. We do this by marking each piece of information in a unique way.
For information in databases, the markings are unique values called keys or identities. A piece of information can have multiple identities, each for a different purpose. For example, although a company’s payroll system is likely to identify each person by a unique Employee ID, each person’s details will also include their governmental tax ID (such as a National Insurance number, a Unique Taxpayer Reference, a Sozialversicherungsnummer or a Social Security Number). This tax ID will also be unique and so could also be used as an identity for that person’s information.
Cradle has two forms of identity, item identities and Project Database Unique IDs (PDUIDs).
We will publish a series of blog posts about PDUIDs, describing what they are, how to view them, how to use them, and how PDUIDs can be managed when you import information into your databases.
Item Identities
There are several basic item types in Cradle. Each basic item type uses a different combination of attributes to create a unique Item ID for items of that type:
An item is identified by this Item ID and a unique Instance ID, typically a version and draft.
PDUID Structure
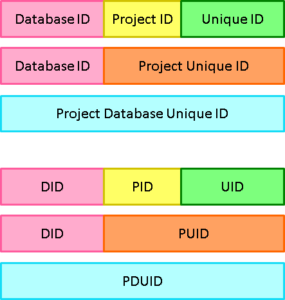
Project Database Unique IDs (PDUIDs) are a single, consistent, numbering system for all database information. Each PDUID is a 26 character string that contains a Database ID to identify a Cradle system, a Project ID to identify a project database and a Unique ID:
Structure of PDUIDs
A PDUID references all instances of an item. Therefore the combination of a PDUID and an Instance ID (a version and draft) will identify a specific item. So, this is an alternative to the Item ID and Instance ID and has the advantage of being consistent and a single numbering sequence for all types of item.
Further Details
For further details in this part 1 of a description of PDUIDs, please see the full blog entry here.
Remote Databases
A Cradle system can contain any number of databases. For the best performance, we recommend that databases are stored on disks connected to the machine that runs your Cradle Database Server (CDS). But, this may not be possible.
For example:
The local system may not have enough disk space available
The information in the database may be classified and must be stored separately
Here each database will be stored on a remote filesystem that must be referenced by a pathname so the CDS can work with it.
Further Details
For further details of remote databases, please see the full blog entry here.
Over Half Way Through the Year
It’s true; the 2nd July marked the halfway point of the calendar year. That went fast didn’t it?
It feels like we only just celebrated the New Year and now we are six months away from doing it all over again.
At this time of year, it is good to reflect on what’s already passed and what is to come this year. Here are some ways that might help if you are looking to refocus and recharge over the summer months.
Check in on Team Goals
How are the goals the team set at the beginning of the year going?
When was the last time your team reviewed them?
Now is a great time to reflect on any progress. Is your team on track? Is everybody on the same page?
Whatever the progress so far this year, there will be lessons to be learnt from it. It’s time to put an action plan in place for the remainder of the year. Now is a good time to get the team goals back on track:
Ask who do you need to help achieve those goals?
What’s the best way to communicate with them?
Is there an alternative way to achieve them?
Communication
Summer can be especially busy; school summer holidays, weekly events, fewer people in the office, and various demands can bring stress to everyone.
With all these additional activities going on, it’s easy for people to get distracted, lost and even burnt out.
Now is a great time to contact your team, employees and other connections. It can be as simple as a chat over a cup of coffee, a walk and talk or a business/working lunch. This will allow you to connect in a more casual way, which in turn, can help strengthen the link between you and your team.
Help your Team Avoid a Summer Decline
It’s no surprise that productivity can fall off a cliff when the sun comes out! Thoughts of ice cream, beer gardens and future holidays can lead our minds to wander off and our focus can end up in the bin.
Ice cream
Now is a good time to prepare your team and business to avoid any slump.
Congratulate your team on their efforts so far this year. One way to keep the momentum going is to set small achievable goals, something that can be done within a week to a month can help. As you complete and reach each one, the team will get a boost.
Having weekly/monthly meetings can allow the team to see those goals that have been achieved. Using metrics, dashboards and graphs can help your team see the progress made each week, month, year or more.
This progress will give reasons to celebrate and that can only be a good thing!
Remember: the team working together will make the dream work!
Feedback
We continue to receive positive feedback from our customers. We really appreciate ALL feedback, as this helps us to assess and improve both the products and services we provide.
In June, we provided a Cradle training course to one of our customers in Australia. They kindly sent the following feedback:
“Extremely informative classes. We are very appreciative of the customised content tailored for our envisaged use of the tool”
Independence Day (4th July)
4th July was a federal holiday in the United States commemorating the Declaration of Independence which was ratified by the Second Continental Congress on July 4th 1776, establishing the United States of America.
Social Media
We commemorated #DDay – 79 years ago. “We will remember them“:
DDay
Some of our customers, both old and new, attended various shows/exhibitions etc, e.g.:
@SercoGroup announced they have been awarded nine contracts to help the #IRIDE space programme. This programme is led by the Italian government and implemented by the European Space Agency. This is one of the most amibitous Earth Observation programmes in Europe.
With electric vehicles taking over the roads, our customer @Enphase talked about EV chargers.
This is the first in a short series of posts that explain Project Database Unique IDs (PDUIDs). This post explains the purpose of PDUIDs and their structure. Later posts will explain:
How PDUIDs can be viewed
How they can be used in operations in Cradle tools, API and WSI
How PDUIDs can be changed or preserved when information is moved between databases
Identifying Information
Each piece of information must be distinguishable from all other pieces of information so we can be sure we have found what we were searching for. We do this by marking each piece of information in a unique way.
For information in databases, the markings are unique values called keys or identities. A piece of information can have multiple identities, each for a different purpose. For example, although a company’s payroll system is likely to identify each person by a unique Employee ID, each person’s details will also include their governmental tax ID (such as a National Insurance number, a Unique Taxpayer Reference, a Sozialversicherungsnummer or a Social Security Number). This tax ID will also be unique and so could also be used as an identity for that person’s information.
Cradle has two forms of identity, item identities and Project Database Unique IDs (PDUIDs).
Database and Host Identities
Every Cradle system has a Cradle Database Server (CDS) to manage the information in its databases. The CDS is locked to a Host ID, the last 8 digits of the MAC address of the host’s primary network interface.
All databases in a Cradle system share a common Database ID (DID), a 10-character ID of the form:
Platform ID Host ID
where:
Platform ID
:
CDS’s platform, 02 for Windows or 17 for Linux (other values are for obsolete platforms such as Domain/OS, SunOS, Solaris, HP-UX, Ultrix, SCO, OSF/1 and VMS)
Host ID
:
CDS’s host ID, also used in the system’s Security Code
For example: 1750D4FA4C
The role of a DID is to differentiate information in a database managed by one CDS from information in databases managed by any other CDS, even if all other particulars of the information are the same, such as they are the same item of the same item type in the same project in these disparate Cradle systems.
A common example is when organisations send information to each other, such as customers and suppliers. This creates two copies, or instances, of each piece of information. The databases’ DIDs differentiate the instances held by the customer and suppliers. This is important because:
An organisation cannot know if other organisations have changed information
It is important to know which organisations hold each piece of information and which pieces of information each organisation holds
It may be appropriate to designate one instance as primary so its content is authoritative and other instances are secondary
Project Identities
A Cradle system can manage many databases. Each database is used for one or more projects. Each database has a unique 4 character Project Code that is used at login to specify which database is to be accessed.
Separately, a Project ID (PID) can be specified when a database is created using the Project Manager tool, or c_prj utility. This is a 6-character string and is typically similar to the Project Code. It defaults to six underscores:
______
The Project ID can be used to label a database. It can be helpful if databases are related, for example as successive missions in a programme or separate vessels in a class of ships, when related Project IDs could be used:
ARTEM01
ARTEM02
ARTEM03
Role of Project IDs
It is likely that what might appear to be the same information could exist in two or more databases. This could be intentional and helpful, or it could be unhelpful and inconvenient. The fundamental role of a PID is to differentiate between databases:
In the most common scenario, an organisation uses its standard process in several projects. These projects’ databases will contain the same types of information, such as hierarchies of needs and user requirements, and the same structuring and numbering conventions. It is quite likely that the databases will contain items with the same hierarchical numbers and, for groups and sub-groups, the same names:
1 Context
1.1 Purpose
1.2 Roles
1.2.1
2 Stakeholders
2.1 Purchasers
2.2 Operators
Here it is inconvenient that multiple requirement 1.2.1s exist in the databases, each with unrelated contents. Viewing requirement 1.2.1 in isolation could give an incorrect understanding by interpreting it as part of one project when it is actually part of another project.
In an alternate scenario, two or more databases could be logically related. Indeed one database may be an extension of another, or an evolution of it at a later stage in the project. In this case, viewing information in isolation would not show which database it came from and could also create an incorrect understanding.
In both scenarios, including a PID would differentiate the content of each database from the others.
Item Identities
Cradle databases contain different types of information. The basic unit of information in a Cradle database is the item. Every item has an associated item type that defines the type of information it contains. Projects can create their own item types in the schema that describes the database’s structure and rules. For example:
HLURs, high level user requirements
SRs, system requirements
TEST CASE, description of a test to be run with the steps to perform and their possible outcomes
Collectively the items of such user-defined item types are called system notes.
Identities and Instances
Every item has an identity to uniquely identify it amongst other items. An identity is the combination of the values of several attributes.
Items evolve over time. Projects will usually keep copies of items at different stages in their evolution. Cradle has the concept of instances of an item. Instances are copies of items as they were at some time in the past, typically in previous baselines. In MBSE (model based systems engineering) users can create multiple instances of diagrams and specifications as alternative analyses or designs. These alternatives co-exist until a choice is made between them.
An instance is the combination of:
A version number, initially empty and increasing 1, 2, 3… through successive baselines
A draft ID, either A if the item is not in a baseline or empty if the item is baselined. The values B, C … Z are used for alternative diagram and specification items in MBSE analysis or design models.
Structure of an Identity
The identity of an item is:
Item ID Instance ID
where:
Item ID
:
The collection of attributes that identify a specific item of a given item type
Instance ID
:
Which of possibly many instances of the item is being referred to
The different parts of item identities are:
Components of Item Identities
where:
Domain ID
:
Either E (for Essential) or I (for Implementation), the domain containing the item’s model
Model ID
:
The item’s model, either a numeric Model Unique ID (MUID) or a namespace showing the model in the domain’s model hierarchy, such as: As Built.Prototype A.Architecture
Type
:
Either one of the 26 diagram types that Cradle supports such as DFD, eFFBD, UCD, PAD and so on, or a specification type (process specification, environment terminator or module specification) or a user-defined item type such as PRODUCT REQ, SBS or VALIDATION
Stereotype
:
Only used by information in SysML models, the item’s stereotype, such as <<actor>>, <<block>>, <<constraint>>, <<message>>, <<package>> and so on
The item identity is fundamental in Cradle. All other methods of identifying or labelling items, including those described in this document, are secondary to these item identities.
PDUIDs
The above tables show that there are significant differences between the identities of item types. They make specifying and working with identities complex, and do not provide a single sequence of values to identify all items in a database.
These problems are solved by the Project Database Unique ID (PDUID), which:
Apply to all of the item types
Have the same format for all of these item types
Are in a single sequence for all items, for example:
A PDUID could reference a diagram in a model with namespace B.C (with an equivalent MUID)
The next PDUID could reference a TEST CASE system note item
The next PDUID could be a diagram in a namespace Y model (different MUID to the above diagram)
The next PDUID could reference a change request
The next PDUID could be a data definition in the model with namespace B.C
PDUID Structure
The format of a PDUID is:
Database IDProject IDUnique ID
where the Database ID and Project ID are as described earlier, and the Unique ID is a number 1, 2, 3… zero-padded to 10 digits. PDUIDs are 26 character strings with the structure:
Structure of PDUIDs
PDUID Examples
Some example PDUIDs:
0280A992E5SYSML_0000000022, in which:
0280A992E5 : is the DID, the Database ID
SYSML_ : is the PID, the Project ID
0000000022 : is the UID, the Unique ID
0280A992E5SYSML_0000000023
0280A992E5 : is the DID, the Database ID
SYSML_ : is the PID, the Project ID
0000000023 : is the UID, the Unique ID
0280A992E5SYSML_0000000024
0280A992E5SYSML_0000000025
Role of PDUID Components
As such, and given their constituent parts:
The Unique ID enables the PDUID to uniquely identify a database item
The Project ID enables the PDUID to uniquely identify an item across multiple databases
The Database ID enables the PDUID to uniquely identify an item between separate Cradle systems, even if everything else about information in the databases in these Cradle systems is the same
PDUIDs as Item Identities
A PDUID identifies an item, but not a specific instance of that item. This is deliberate. It is more convenient if the PDUIDs of all instances of an item are the same. Therefore, an alternative for the identity of an item is:
PDUID Instance ID
which identifies a specific instance of an item, where:
PDUID
:
Is the item’s PDUID as defined above that identifies an item
Instance ID
:
Which of possibly many instances of the item is being referred to, with the same meaning as above
PDUID Item Identity Examples
As examples, in the example database SYSM:
There is a use case diagram Automobile Use Case Diagram whose identity is:
Domain ID: I
Namespace: SysML-Automobile, which has MUID 100
Type: uc, meaning a SysML use case diagram
Stereotype: use case
Number: uc-1
Version:
Draft: A
which has been assigned the PDUID 0280A992E5SYSML_0000000035 so the item’s identity is also:
PDUID: 0280A992E5SYSML_0000000035
Version:
Draft: A
that can also be expressed as:
Database ID: 0280A992E5
Project ID: SYSML_, and hence PUID: SYSML_0000000035
Unique ID: 0000000035
In the same database there is also a TEST CASE item Keycode verification whose identity is:
Type: TEST CASE
Number: TC-20
Version:
Draft: A
which has been assigned the PDUID 0280A992E5SYSML_0000000024 so the item’s identity is also:
PDUID: 0280A992E5SYSML_0000000024
Version:
Draft: A
that can also be expressed as:
Database ID: 0280A992E5
Project ID: SYSML_, and hence PUID: SYSML_0000000024
Unique ID: 0000000024
Version:
Draft: A
PUIDs
Project Unique ID (PUID) is the name given to the PDUID without its Database ID (DID). In other words, PUIDs are a means to identify pieces of information in a single database.
PDUID Lookup
Every Cradle database contains a table that is used to check if a PDUID has been used and to convert between item identities and PDUIDs. This table is empty when a database is first created. The table is not part of the information in Cradle export files. Rather, the table’s contents are created when items are created in the database, either by an operation in the database such as creating or copying items, or reordering a hierarchy of items, or by importing information into the database from an external file.
This table is used to:
Check if a PDUID has been used
Find the PDUID for a given item identity
Find the item identity for a given PDUID
Find the next UID to be used
Entries in the table are marked deleted when the last instance of the corresponding database item is deleted.
Selective Reuse of PDUIDs
PDUIDs are never reused for different pieces of information, but they are reused for the same piece of information. This means that if a piece of information is deleted, its entry in the PDUID table is marked deleted, but the entry remains in the table. If that piece of information is ever recreated, then the PDUID table entry will be found, marked active, and the PDUID recorded in the table entry will be applied to the piece of information.
If items are auto-numbered, then the items’ identities are never reused and so PDUIDs are never reused.
For items that are not auto-numbered, or do not support auto-numbering (such as diagram, specification or data definition items in models), then PDUIDs can be reused. PDUIDs can also be reused when information is imported, and previously-deleted items are found in the PDUID table and their PDUIDs reused. This can be over-ridden on import as will be discussed later.
Example Scenario
As an example, consider the scenario:
Create item r1, the assigned PDUID is: 020A3857A3FRED__0000000001
Create item r2, the assigned PDUID is: 020A3857A3FRED__0000000002
Delete item r1
Create item r3, the assigned PDUID is 020A3857A3FRED__0000000003. Note that the UID in this PDUID is not 1 (which is now available since r1 was deleted), it is 3, because new PDUIDs always use the next UID value.
Create item r4, the assigned PDUID is: 020A3857A3FRED__0000000004
Create item r1, the assigned PDUID is: 020A3857A3FRED__0000000001 because the original PDUID table entry for r1 has been found and marked active and its PDUID has been reused so that the new item r1 is assigned the same PDUID as the original item r1.
Reuse of PDUIDs on Import
The reuse of PDUIDs is the correct approach as it ensures that a given item always has the same identity, regardless of what happens during the life of a project.
If, for whatever reason, this is not the behaviour that you want, then use auto-numbered items so that every item will be guaranteed to have a new identity and hence guaranteed to also have a new PDUID. Since auto-numbering makes the reuse of item identities impossible; auto-numbering also ensures that it is impossible to reuse PDUIDs.