The Cradle SWE module provides reverse engineering and code generation to maintain consistency between a detailed system design and its software implementation.
Cradle Software Engineering SWE Module
Software Engineering
There are many contexts for software engineering, each using its own methods and languages. This module is intended for groups using functional methods to build software in C, Ada or Pascal.
Detailed software designs are represented using Structure Charts (STCs) with 3SL extensions to support:
Hierarchical descriptions of software into systems
Programs
Subsystems
Modules and source files
Representation of functions
Representation of basic data types
Software designs are described with diagrams, data definitions and module specifications that hold the pseudo code, descriptions or source code. This software design is cross referenced to architecture, design/analysis models, to requirements/test cases, and to all other data.
The initial design can be code generated to:
C, Ada and Pascal type definition header files (built from the model’s data definitions)
Source files that contain the call hierarchy from the STCs
Call arguments and local variable declarations
Content of the STC’s module specifications’ pseudo code or detailed design material.
Once algorithmic content is added to the generated code, the resulting completed source files can be reverse engineered back into the Cradle database, to update its design diagrams, and both the data definitions and module specifications of these diagrams’ symbols.
Reverse Engineering
Reverse engineering merges the actual source code into the design definitions and specifications. Each source file is subdivided into the individual routines. The component parts are then stored into separate frames in the module specification and data definition items in the database. Every line in each source file is stored in a frame of one of these items in the database.
The Code Generator can be run on the results of the reverse engineering to reconstruct the source files, either as they were, or including any changes made in the design model. In this case, the source code is generated using call interfaces built from the (possibly modified) STCs and the routines’ bodies are created from either the STC call hierarchy or the source code from the previous reverse engineer operation.
The process can start by reverse engineering legacy source code into an initial design model, recovering designs in situations where only the implementation currently exists.
As reverse engineering loads all source files into the database, the source files could be deleted, and instead configuration managed through the Cradle Configuration Management System as part of the design.
The diagrams, specifications and data definitions can contain any number of attributes, including URLs to reference the source code in a source code control system, such as Git or Subversion.
Format of Generated Code
The format of all generated code can be tailored to match your coding standards. Data definitions can be marked to be standard data types and generated into the source code. Header files can be produced from the composition specifications inside the data definitions to create record and variant structure declarations.
Support
The reverse engineering tool supports any compiler programs and conditional compilation directives. It can distinguish application code, application libraries and standard library or operating system / runtime routines, and render the design diagrams accordingly. This uses any combination of regular expressions, and Cradle-supplied or user-defined library routine lists.
Reverse engineering can process one or more source files in one run, creating a hierarchy of design diagrams to represent the code structure beyond individual source files.
Full Traceability
Using the reverse engineering tool creates full traceability across the entire system lifecycle, from user needs to system requirements to analysis, architecture and design models, to test procedures, specifications and test cases, to the source code. Cradle’s transitive cross reference view facilities allow users to directly see the user requirements and acceptance criteria associated with each source code module, and vice versa.
Feature Summary
Feature Summary – SWE
Please contact 3SL for further information about adding a Cradle SWE module to your existing system.
In general, users will access a Cradle database through a Cradle web UI or a non-web UI such as WorkBench.
There are situations where direct access is not possible, particularly if the users are remote from the database and do not have any external electronic access, of if the data is classified and cannot be sent across a public network, such as the Internet, even if the connections are secured.
In such cases, database information is normally published into one or more documents that are provided to the external users. This works well, except that documents are linear, a sequence of pages, and it is not always easy to explore their contents. This is particularly true for analysis and design models where there are many connections between the models’ components, and also when following cross references between items.
Website Pages
The Web Publisher tool generates a static website containing some or all of the items in a database. This website contains three types of page:
A top-level page
Pages containing lists of each item type that has been published
Individual pages for each item
The pages for individual items contains lists of links to related items of each type, grouped by the type of cross reference.
Diagrams are published as SVG so they can be zoomed, panned and scrolled. All diagram symbols are hyperlinked to lower-level diagrams and to the symbols’ descriptions in specifications and data definitions.
Website Links
So the pages for individual items are connected by hyperlinks in the same way that the database items are connected by cross references.
Users can follow these hyperlinks to explore the information in any way that is convenient to them.
Website Distribution
By being static, the website is fully independent of Cradle. By being read-only, the websites can be distributed on CD or DVD, In effect, the website is a self-contained snapshot of the parts of the database that you have chosen to publish.
Templates/Themes
User-defined criteria specify the item types, and items of these types, to be published from the database. The form and content of the website’s main page can be controlled with a user-defined template. The tables for each item type have user-defined columns and contain any attributes. The pages for items have individual user-defined templates so that the layout and attributes to be published can be controlled.
Collectively these templates are called a theme. Several themes are provided with Web Publisher. You can create your own themes to include your company or project logos and branding.
Items in a Cradle database can contain any number of attributes of a wide variety of types, including URLs. So any item in Cradle can contain URLs that link it to other resources, either on the Internet, or intranet, or data in another environment.
You can include these URL attributes in your templates for the Web Publisher. By doing so, the pages published by the Web Publisher will contain these URLs so that a user browsing the published website can follow the URLs to access the related information, wherever it may be.
Publishing
Websites are published into a user-defined top-level file and a directory containing all other pages. It is easy to link the generated site into a larger set of information, including any site-specific modifications to the hyperlink URLs.
Different baselines, or work-in-progress, can be published to separate websites, for comparison between approved and current activities.
Feature Summary
Feature Summary – WEBP
Please contact 3SL for further information about adding a Cradle WEBP module to your existing system.
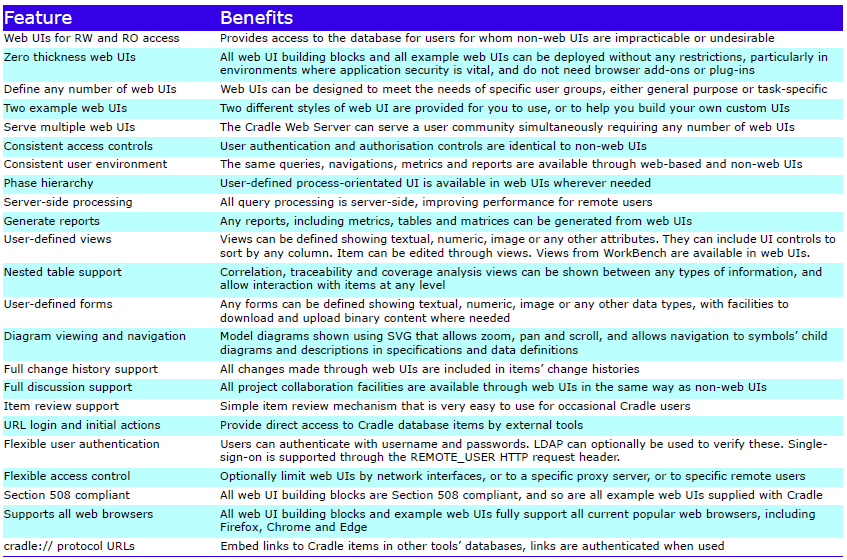
The Cradle WEBA module provides the means to create custom web UIs that allow users to access Cradle databases from web browsers in a manner that is appropriate to their needs and use cases.
Web Access
Cradle provides WorkBench as the means to access databases and provides many choices to create a customised environment, including start pages and the phase hierarchy. However, WorkBench is not suitable for all users:
Users may not want to install Cradle
Users may be remote from the Cradle system and WorkBench may not provide acceptable performance (despite server-side processing)
Users may not allow Cradle to communicate through their firewall
WorkBench provides more functionality than needed and, therefore, appears too complex
Why use Web UIs?
So there are at least three reasons why a project may wish to create web UIs:
IT restrictions in the use of WorkBench
Performance needs of remote users
Provide simple UIs tailored to the needs of specific user groups
Cradle allows web UIs to create, manipulate or view database information. Each web UI is created to meet the needs of a group of users, either to offer a wide range of UI controls to provide a flexible and powerful UI so users can perform many tasks, or a simple UI that allows users to perform perhaps one or two tasks very quickly and easily.
All web UIs are zero thickness, with no client-side code. There are no browser add-ins or plug-ins needed.
Creating Web UIs
Any number of web UIs can be created. Each is associated with a project-specific user type. Each Cradle login account is also associated with a user type. When a user connects to the Cradle Web Server (CWS) and logs in, the CWS serves the web UI defined for the user’s user type, or a default web UI.
Therefore, the CWS can serve many, potentially very different, web UIs to its users, based on their user types.
Users login to a web UI with the same username and password used with non-web tools. Web-based users have the same access rights to items and Cradle operations as users of non-web tools such as WorkBench and utilities.
Web UIs are created from templates and building blocks provided in the Cradle WEBA module. The module also includes two example web UIs:
A web UI using all blocks to offer a powerful and flexible environment for engineers
A basic UI providing controls over page layout, item creation, viewing and reporting
Using the Cradle WEBA Module
In the example web UIs, users can create, view, edit and delete items and they can manipulate and follow cross references:
Users can navigate through the database using the phase hierarchy, the master tree, or using a table-based browse mechanism,
Items edited in web UIs are locked in the same way as non-web UIs and the API, to prevent simultaneous update by other web or non-web users.
Tables of items shown in web UIs will load into Word and Excel as hyperlinked documents.
Web users can create and use the same queries as non-web UI users. All query processing is server-side in the CWS to optimise the performance for each user.
Views created in WorkBench can be used in web UIs. Items can be edited in table views. Items can be shown in user-defined forms. Binary data can be modified and uploaded in a web UI. Rich text can be shown in web UIs.
Diagrams are shown in SVG. Diagrams can be zoomed and panned. Hyperlinks in each diagram symbol allow users to navigate to child diagrams and from symbols to their descriptions in data definitions and specifications.
Change histories are also fully supported, together with all collaboration facilities, including discussions and alerts.
Authentication to web UIs can use LDAP and support single sign-on. Access to web UIs can be limited to specific proxy servers, network interfaces and remote hosts.
Cradle provides cradle:// protocol URLs that allow direct access to items and query results by external tools.
Feature Summary
Feature Summary – WEBA
Please contact 3SL for further information about adding a Cradle WEBA module to your existing system.
There are situations, as with any database, where integrity issues may occur with the data not matching what is defined in the schema. This could be due to a number of reasons such as:
Items of data that have not yet been populated
Mandatory categories or frames that have not been populated
With Cradle also providing the facility for data to be imported and captured in a number of different ways, it is inevitable that the integrity of this data may be questionable. Document Loader, capture add-ins and import are some of these mechanisms and, despite some protective settings in these tools, it is still possible to bring in data that does not match the current schema.
In addition to this, it is possible to import a project schema itself or modify the project setup which would impact the data that already exists in the database:
Changing item attributes, categories and frames
Changing link rules
For these reasons, Cradle provides two utilities in WorkBench that check the data in comparison to Project Setup:
Item Integrity Check
Cross Reference Integrity Check
For both of these utilities, the user MUST have ACCESS_BYPASS privilege to instigate any changes to the data. It is highly recommended that there are no other active users in the database when the checkers are ran. One way to ensure this is to lock the project using Project Manager.
We also recommend that you take a backup of your database and/or create a snapshot prior to making any changes with these utilities.
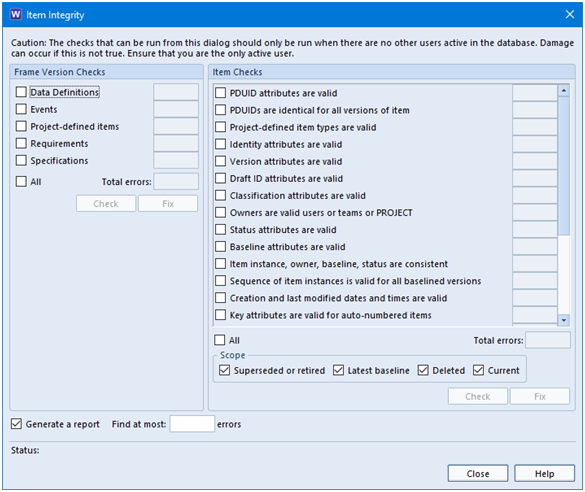
The Item Integrity Checker is split into two parts:
Frame version checks
Item checks
Item Integrity Checker
Frame Version Checks
Cradle item types contain a type of attribute called a frame. Each frame can store or manage up to 1 TByte of any kind of data. An item can contain any number of frame attributes.
In practice, most frames store a small amount of text.
These item types also have a mechanism called edit history that records any changes that are made to an item. Each edit contains:
The date and time the edit occurred
The Cradle username of the person who performed the edit
The reason the edit was performed, this description is optional
A list of all the attributes (predefined, category values and frames) that were changed in the edit and their old and new values
For frames, it records the frame version numbers before and after the edit. All the frames versions are held within the item’s frame.
These frame version checks detect:
Missing version of any frames
Missing records in any version of any frame
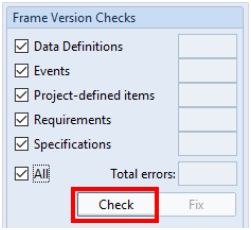
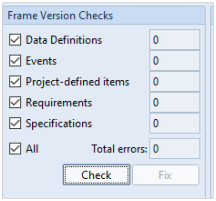
To run this utility, select the item type(s) you want to check or All to check all item types. Then press the left-most Check button.
Frame Version Checks
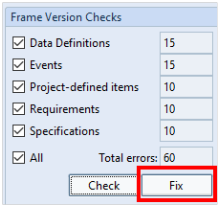
This will check all of the items in each item type selected to ensure each frame has a version of 0 and that all history for that frame, occurs in an accumulative sequence of 0, 1, 2, 3 etc and produce both a report and a summary in the dialog.
Frame Integrity Check report
Notice in the dialog, that the Fix button becomes activated.
Fix button in frame version checks
Pressing this button will repair the history records and can be checked by repeating the process:
Recheck frame versionsFrame Integrity Check Report – No issues
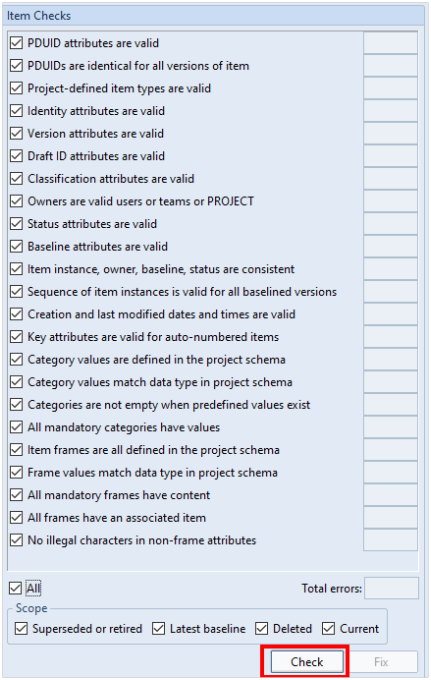
Item Checks
On the right-hand side of the Item Integrity Check dialog, you will see a list of item checks that can be selected, or press All to select and run all checks.
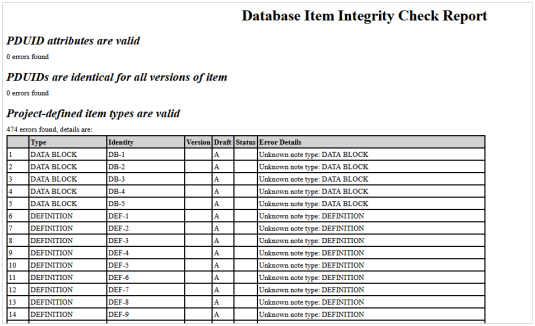
These item checks compare the data that is held in the database with the currently defined settings in Project Setup to ensure they are consistent. If they are not, the utility will list any possible issues.
Item Checks
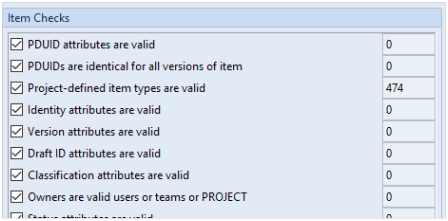
Once you have pressed the Check button, a report is produced and a summary appears in the dialog:
As with the frame integrity check, there is a Fix button but this can only apply to a number of checks. The ones that cannot be automatically fixed will appear on the report and will require some user intervention to correct the issue.
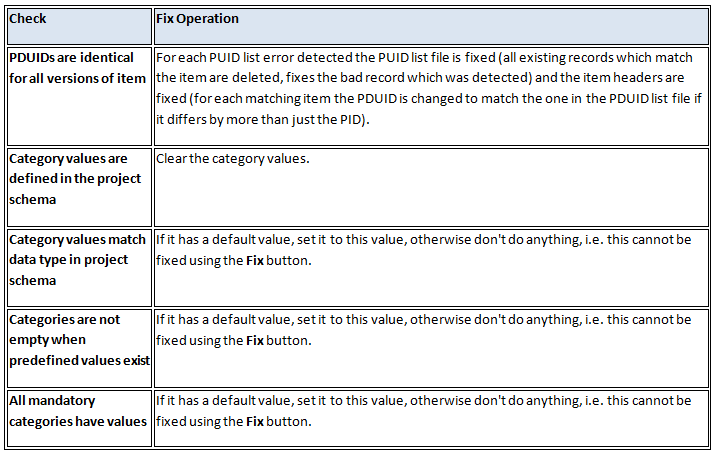
Below is a list of the issues that can be automatically fixed:
Issues that can be fixed
Summary
In this post we have addressed some of the checks that can be run on items in the database to confirm their data integrity using the Item Integrity Checker.
Please remember that the user MUST have ACCESS_BYPASS privilege to instigate any changes to the data and it is highly recommended that there are no other active users in the database.
Next we will discuss the Cross Reference Integrity Checker.
The Cradle PERF module applies user-defined calculations to an architecture model, to compare the performance of alternative architectures and apportion performance budgets to subsystem, component and equipment designs.
Performance Modelling PERF Module
Simulation is an activity to reproduce a system’s behaviour in an artificial environment to test the system in a variety of scenarios. Simulation is used where testing the real system is either dangerous, impracticable or too time-consuming or expensive. The most fundamental behavioural characteristics of systems are set early in the design process, as alternative architecture topologies are assessed and performance budgets are set. But as there is no behaviour allocated to the components, it is not possible to build a simulation.
Performance Assessment
Performance assessment solves this problem. It is used before behaviour is known and allocated and so before simulation can be used. It can be used:
To confirm if a proposed architecture is viable
To compare performance characteristics of candidate architectures
To define budgets for lower design levels (apportionment)
To aggregate actual values
Performance assessment is expressed in user defined characteristics, typically concerned with timing, data error or precision, such as:
Bandwidth
Utilisation
Size
Cost
Data rate
Staleness
Weight
Power
They can be subdivided, for example to study best case, worst case and typical conditions. They are held as user-defined formulae in the specifications and data definitions of the symbols in the architecture models’ diagrams.
Performance Characteristics
Any number of performance characteristics can be defined and associated with each diagram symbol. Each has its own formula. These are defined using a function library and user-defined calculation routines. This library contains logical, arithmetic, logarithmic, exponential, ladder, table lookup and interpolation routines, amongst others.
System performance requirements are applied as constraints to these characteristics by linking the items in the database and defining ranges of values for the performance characteristics that should not, or may not, be exceeded.
Analyses
Analyses are run on state models that are sets of interconnected diagrams at appropriate levels in the architecture.
A state model can have external loads applied to it to represent different usage scenarios. An analysis can contain many such environmental loads. The environmental loads are defined as values of any of the performance characteristics at the external input(s) to the model.
Each analysis applies the environmental load and calculates performance characteristics for all of the symbols in the state model’s diagrams using the formulae and constraints in each symbol. The results are therefore quantitative. They are stored inside the symbols’ descriptions.
The results can be reported in the same manner as other information in a Cradle database. They can also be graphed. The graphs will typically show the values of specified characteristics along a path through the model, termed a thread. Each graph will show any constraints applied from the system requirements and the effect of the constrains on the analysis results. The data in such graphs can be exported to CSV.
The results will show that an architecture is viable if none of its constraints are violated.
Since the performance data is built into the architecture model, any changes to the model’s topology (such as a change to the architecture) will be automatically reflected in changes to the performance results. This allows easy comparison between alternative architectures.
The analysis results are the characteristics of a viable architecture. Hence, they are the constraints or budgets for the next level of design. So the analysis of each level produces performance constraints for the next level. This process can continue through the design levels until the system behaviour is sufficiently defined for simulation to be practicable.
Feature Summary
Feature Summary – PERF
Please contact 3SL for further information about adding a Cradle PERF module to your existing system.
The Cradle SYS module provides an analysis, process, architecture and design modelling environment that, being linked into the systems engineering lifecycle, provides full traceability and coverage for all model information. You can use SysML, UML, ADARTS, SASD, eFFBD, IDEF, BPM and other notations to achieve your MBSE goals.
Systems Modelling Module
Models
A model is an abstraction of an aspect of a system being developed. Therefore, models should not be separate from the needs, goals and objectives that the model seeks to satisfy, nor from the tests that validate the system’s compliance. Hence Cradle integrates modelling into all requirements and other systems engineering data, so every component of every model is traced to the highest level user need and to the lowest level test result.
This applies to agile and phase-based processes. An agile process has no less need for models simply because its iterations are short. To neglect rigorous design in agile projects will ultimately compromise the system if a clear design is not modelled at the outset and maintained through each iteration.
Domains
Each Cradle database provides analysis and design domains. Each domain can contain any number of models, optionally organised in hierarchies. Models can be used to represent concepts such as:
Alternative missions in a CONOPS
Products within a range
Regional variants of a product
Comparative analysis of architectures
Each model contains any number of diagrams from a wide variety of notations. Each diagram contains symbols, and each symbol is described by a data definition or specification.
All diagrams, specifications and data definitions in a model can be cross referenced to each other and to information in all parts of the lifecycle. So user requirements can be linked to use cases, that are linked to system requirements, that link to a logical model of system behaviour, that can be allocated to a logical architecture, which in turn can be allocated to multiple physical architecture models for assessment.
A System Breakdown Structure (SBS) is useful as an abstraction of the system composition, and as a single structure to which all the requirements can be linked. The alternative system architectures and designs can be explored, each in its own model, all models linked to the SBS. This simplifies traceability for the requirements and the performance constraints, without restricting the modelling activities.
Cradle has over 20 diagram notations from methods including UML, ADARTS, IDEF, SASD, SysML and data, process and architecture modelling. The notations can be combined when semantically viable. Cradle does not limit you to one method, nor constrain your choices for the notations that will best express the system for the audience of that model.
In hierarchical notations, Cradle has a range of features to build both child and parent diagrams that are automatically consistent.
Consistency Checking
Cradle enforces diagram syntax when editing. Completeness and I/O consistency checks are provided, both within a diagram and between diagrams to ensure conservation of data and function. Cradle can also check the consistency of diagram graphics and text descriptions. For notations that use it, Cradle provides a full Data Dictionary with a formal BNF notation to describe data composition.
Bitfields
In architecture models, Cradle supports data protocol descriptions across interfaces and can generate message formats (bitfields) that describe the formatting of the messages in all data exchanges.
Symbols
Diagram symbols can be coloured and have embedded graphics, to ease users’ understanding of the model.
Notations and Models
Notations can be combined, such as using UML and other diagrams in the same model. Some notations can be used in many contexts. For example Sequence Diagrams (SQDs) can show a message protocol across an architecture model interface, their role in SDL before their use in UML.
All model elements can contain graphics, video, figures, tables, equations, URLs and integrate with desktop tools including Visio, Word, and Excel. Each diagram, data definition or specification is an item in the database and so can contain any number of attributes each containing, or referencing, up to 1 TByte of any type of data.
Configuration Management
Models have change histories, discussions, comments, are formally reviewed in Cradle’s CM system, and can be baselined.
Reports
Models can be printed to a variety of devices. They can be part of user-defined documents with requirements, tests and any other information. Models can be published into static, hyperlinked websites that provide links between diagrams and between symbols and the descriptions. All Cradle web UIs support viewing and navigation of models.
Import/Export
Models can be loaded from other tools by import or data conversion from other tools’ data formats or XML.
Feature Summary
Feature Summary – SYS
Please contact 3SL for further information about adding a Cradle SYS module to your existing system.
Welcome to the September 2023 newsletter from 3SL!
This newsletter contains a mixture of news and technical information about us, and our requirements management and systems engineering tool “Cradle”. We would especially like to welcome everyone who has purchased Cradle in the past month and those who are currently evaluating Cradle for their projects and processes.
We hope that 3SL and Cradle can deliver real and measurable benefits that help you to improve the information flow within, the quality and timeliness of, and the traceability, compliance and governance for, all of your current and future projects.
If you have any questions about your use of Cradle, please do not hesitate to contact 3SL Support.
Latest Updates
The latest technical and related topics in our blog are:
Follow these links to see the latest blog updates and then use the blog’s search to find other topics of interest! With over 500 posts in the blog, we are sure that you will find lots to interest you in the details of Cradle and 3SL!
We would also like to thank all attendees on the Requirements Management course that we held in August.
Using PDUIDs
This section explains how PDUIDs can be used in Cradle.
Opening Items
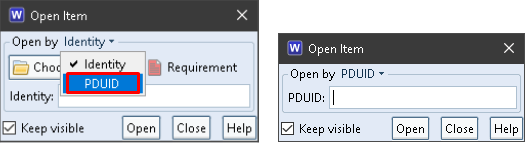
You can open an item by simply specifying its PDUID. You do not need to specify the type of the item using the Item Type Chooser dialogs in the WorkBench and web UIs. For items in models, you do not need to choose the correct domain and then locate the model inside that domain.
You simply specify the PDUID:
Open Item by PDUID
The latest instance of the item will be opened.
Queries
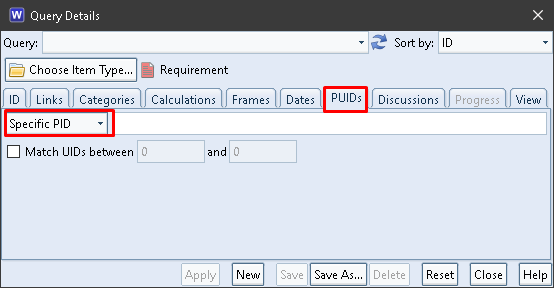
You can find items based on their PDUIDs, or components of the PDUIDs, in addition to any other criteria that you may have set inside the query. Select the PUIDs tab in the Query Details dialog:
PDUIDs in Queries
The selection of items by PDUID will return all instances that you can access RO or RW.
Further Details
For further details on this description of PDUIDs, please see the full blog entry here.
Testimonial
Our Support Team received a wonderful testimonial from one of our customers:
“The support team does an amazing job. Is the better support I ever have in a Software. It was very important decision factor to use CRADLE in the company. “
We try to deliver unrivalled service to all of our customers. If you have been especially pleased, or disappointed, with our support, then let us know!
#Cytovale announced they have partnered with a leading health system (Franciscan Missionaries of Our Lady Health System) to improve sepsis care for their patients
The Cradle DASH module provides the means to define Key Performance Indicators (KPIs) . It also provides the means to define their presentation as dashboards in web UIs, non-web UIs and reports.
Every project uses a process to create, review and publish its objectives, operational concept, sets of requirements, architecture and design models, and other systems engineering data. These processes will include:
Management reporting
Quality checks
Routine audits
of the volume of work completed, and the completeness and quality of this work.
Key Performance Indicators (KPIs)
KPIs are measures of the maturity of the information managed in the process, and therefore of the process itself.
Cradle supports KPIs as a convenient means to provide an overview of the status of an entire project, or any phase.
Any number of KPIs can be defined. Each KPI is a calculation based on one or more elements of one or more metrics:
Product
Sum
Difference
Deduction
Proportion
Percentage
combined to produce a single numerical value. The component values are derived from user-defined queries, that are searches of database items, or searches of the links between these items, or both. The component metrics can:
Count the values or calculate the total, mean, average, range or variance of the values from the items found by the queries
Use values held in attributes or the results from user-defined calculation attributes
These calculation attributes can use other attributes of the same item (this includes other calculations) and also attributes from linked items, such as calculating the total cost from the individual costs of a parent and its children.
Any number of colour-coded range bands can be defined for each KPI so that its value can be shown in a block with an appropriate background colour.
Using colours for the KPIs allows the overall project status to be seen at a glance. Typically, anything shown in green is good, anything shown in red will need urgent attention, and anything yellow needs to be monitored carefully. It is easy to apply such traffic light conventions in a KPI’s colour bands.
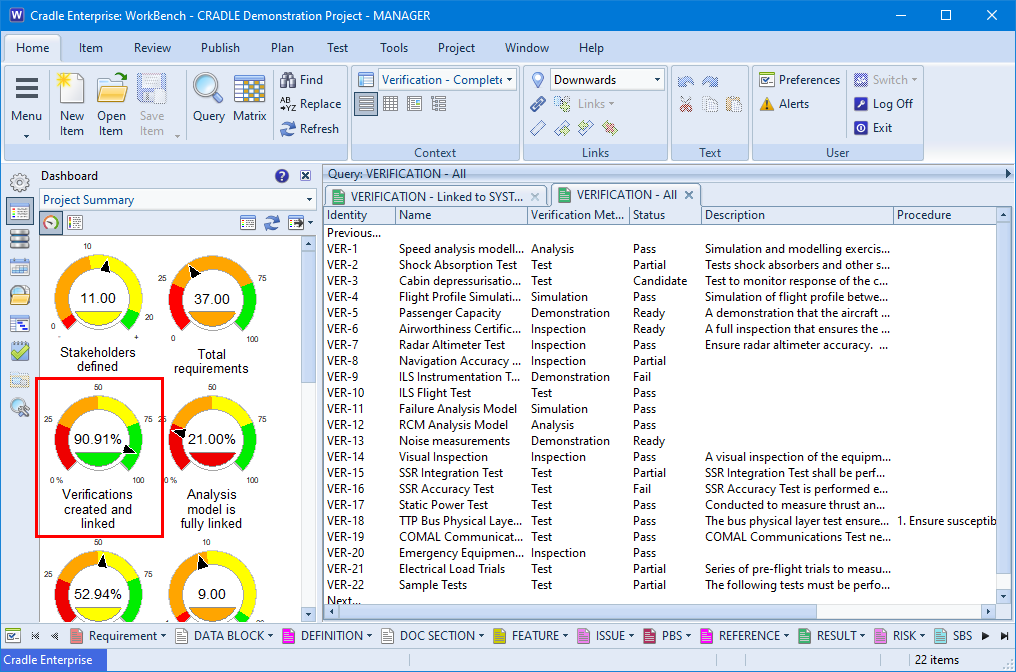
Dashboard in WorkBench
Dashboards
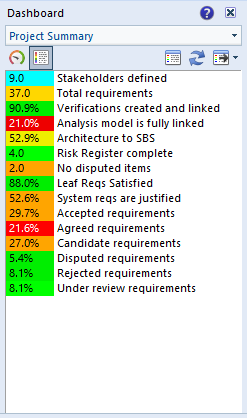
A collection of KPIs is held in a dashboard. Any number of dashboards can be defined, either personal to you, shared with other members of your team, or shared with everyone in the project, or available to all projects.
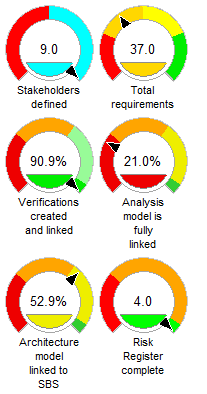
Each dashboard presents its KPIs as a column with the KPI shown either as a name and colour-coded number:
Dashboard in table view
or as a dial:
Dashboard in dial view
The size and display styles of the dials can be controlled for each KPI.
The dashboard can be published as a report, either as a table or as a set of dials. As for all reports, output can be to a file, a printer or the UI. Such dashboard reports are fully supported in web UIs, and non-web UIs.
Dashboard output to a report
The value shown in each KPI is a link. Selecting this value will display the list of items that have been used to create the KPI’s value.
Dashboards are shown in a separate sidebar in both web UIs and non-web UIs. One dashboard can be set as the default and can be shown automatically when the UI starts.
Dashboard showing dashboard sidebar
Custom web UIs could be created to show a collection of dashboards, for example to provide a simple overview of the project and more detailed analyses of the status of each work area.
Dashboards can be published to RTF, HTML and CSV files.
Feature Summary
Feature Summary – DASH
Please contact 3SL for further information about adding a Cradle DASH licence to your existing system.
The Cradle MET module provides the means to define metrics on the:
Needs
Requirements
User stories
Features
Models
Tests
It also defines metrics on all other systems engineering data in your project. Metrics are ran to monitor your progress.
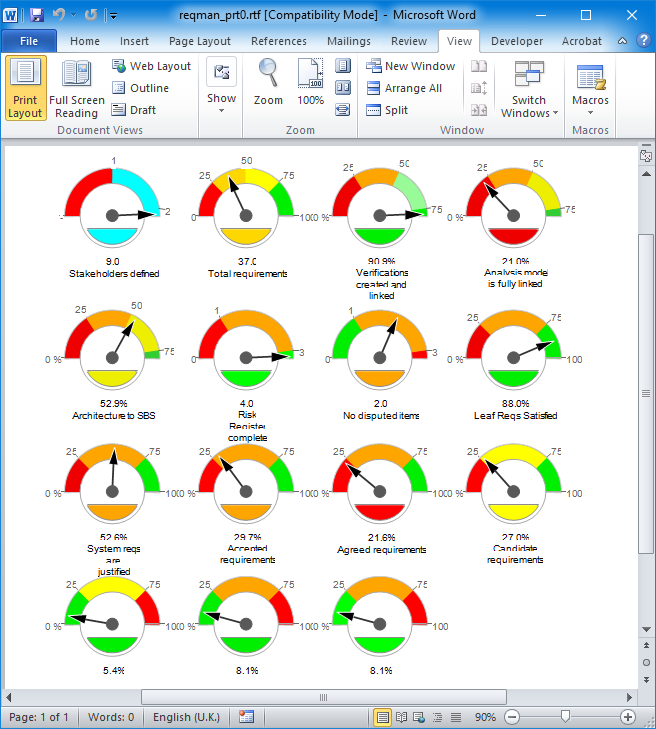
Metric example
Each project uses a process to create, review and publish its: objectives, operational concept, sets of requirements, architecture and design models, and other systems engineering data. These processes include management reporting, quality checks and routine audits of the volume of work that has been completed, and the completeness and quality of this work.
Metrics are a means to measure characteristics of your project data by collecting information about the materials created at each stage in the process. For agile projects, these characteristics will be analysed at the start and end of each iteration or sprint, and in phase based processes, the analyses are likely to be weekly or monthly as part of normal project management activities.
Metrics are user-defined sets of calculations that can be run from the user-defined phase hierarchy and start pages, from the metrics tool’s own UI, as a report, or from a command-line utility.
You can collect metrics on any of your project data. This includes requirements, use cases, functions, architecture components, models, interfaces, issues, risks, features, test specifications, test results, verifications and any other information generated by the systems engineering process.
Metric Elements
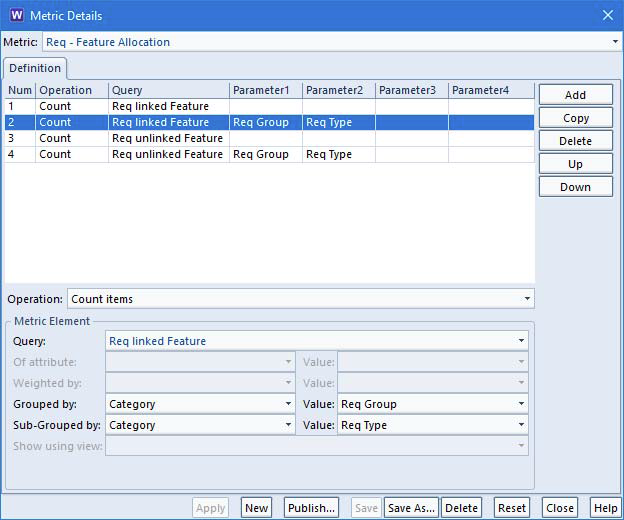
Each metric contains any number of elements, each of which is the combination of a query that finds the information in the database to be analysed, and an analysis to be performed on this set of items found by the query.
Metric Details dialog
Each metric element can use a simple query, or a complex query that nests one query inside another. The items found by the query can be counted, or the metric can perform a coverage analysis of the values of all of their category codes, or it can perform a calculation on the values of one or more attributes, including those attributes that are the results of other user-defined calculations. The results of these operations can be grouped in up to two levels based on the values of other attributes. You can also calculate weighted totals and means of a set of values. This can be used to calculate compliance of responses to a RTF or ITT. Basic calculations can be performed which are based on the results of other metric elements.
Pivot Tables
Metrics can also include pivot tables, which are a special tabular display using two of the items’ attributes’ values as rows and columns where the cells show the number of items from those found by the query that have each pair of values for these attributes.
If a pivot table is shown in the UI, the cells in the pivot table become links. Selecting a link displays the items that have that pair of attribute values. Thus, users can decompose the totals shown in the pivot table’s cells into lists of items with corresponding attribute values.
Running Metrics
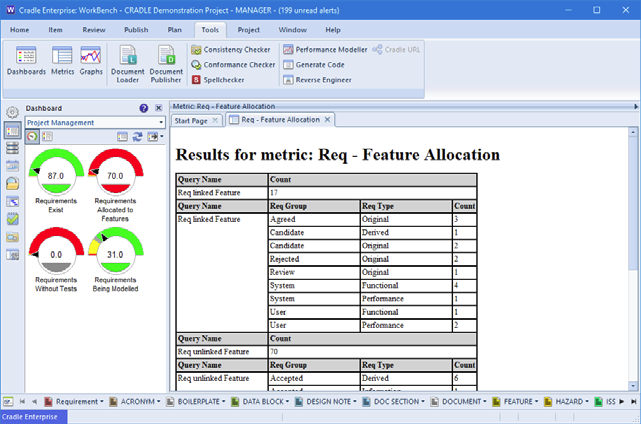
The results of running a metric can be shown in Cradle web UIs and in the WorkBench UI. They can also be generated to RTF, HTML and CSV files and loaded directly into a variety of tools including web browsers, Word and Excel.
Metric displayed in WorkBench
Access to the metrics facility can be controlled, to ensure reliable metrics are produced only in project-approve contents.
This mechanism allows projects to monitor:
The completeness of sets of needs or requirements
The completeness of their cross reference linkage
The volume of data generated by specific project groups.
Metrics can be generated from any project baseline(s), allowing cumulative statistics to be created as the project develops. You can view the database as it was at the time of any historic baseline, and generate metrics from that baseline.
Metrics can be referenced from within KPIs in dashboards using the Cradle DASH module.
Feature Summary
Feature Summary – MET
Please contact 3SL for further information about adding a Cradle MET licence to your existing system.
This is the third in a short series of posts that explain Project Database Unique IDs (PDUIDs). This post explains how PDUIDs can be used in Cradle. The next and final post in the series will explain how PDUIDs can be controlled when information is moved between databases.
Opening Items
You can open an item by simply specifying its PDUID. You do not need to specify the type of the item using the Item Type Chooser dialogs in the WorkBench and web UIs. For items in models, you do not need to choose the correct domain and then locate the model inside that domain.
You simply specify the PDUID:
Open Item by PDUID
The latest instance of the item will be opened.
Queries
You can find items based on their PDUIDs, or components of the PDUIDs, in addition to any other criteria that you may have set inside the query. Select the PUIDs tab in the Query Details dialog:
PDUIDs in Queries
The selection of items by PDUID will return all instances that you can access RO or RW.
Specific PID
If you choose Specific PID then you can enter a PID and an optional UID range. If you only enter a PID, then the query will return all items whose PDUIDs contain that PID. This could be useful if you have been importing data from other databases and so the items in your database have PDUIDs with different PIDs.
For example, if you have separate databases that have different PIDs for:
Different missions in a programme, or
Different vessels in a class of vessels
and you have combined the data from several of these databases into one database, then this option will allow you to find only the items with a single PID, such as for a single mission or for a single vessel. You can optionally filter the items further by specifying a UID range. You can omit the leading zeroes from the UIDs.
Specific PUID
If you choose Specific PUID then you can enter a PUID (the PID and UID) and the query will return all instances of the item with that specific PUID that you can access RO or RW and subject to the other constraints in the query (such as returning only the latest instance that you may have specified in the ID tab).
PUID From
If you choose PUID from then you can enter a PUID (the PID and UID) and the query will return all instances of all items whose PUIDs are greater than the value you specified which will be the combination of:
All items with the same PID and whose UIDs are greater than your specified value
All items with PIDs greater than your specified value and any UID
that you can access RO or RW and subject to the other constraints in the query (such as returning only the latest instance that you may have set in the ID tab).
Referencing Data in Other Items
Items in a Cradle database can hold their information in any number of frames. Each frame is of a user-defined frame type that defines the characteristics of the frame. The data in frames of a frame type is normally stored in the Cradle database, but this can be controlled by the storage mechanism of the frame’s frame type:
In PDB
:
The frame’s data is stored in the Cradle database
As File
:
The frame’s data is stored in an external file whose pathname, size, last access and modified times are stored in the Cradle database
By Command
:
The frame’s data is held in an external environment under an identity, the database stores this identity, and uses Get and Set commands in the frame type to move the data between the environment (specified by the $IDENTITYCommand Directive) and a temporary file (specified by the $PATH Command Directive) where it can be operated on. For example:
This example exports the frame’s contents and sends to the application supplied in the frame type’s View or Edit command and saves the contents from the application back into the frame.
As Reference
:
The frame’s data is stored at a location outside Cradle and the frame stores this external location (such as a pathname or a URL). The data’s location is given to the frame type’s View command, which does not wait for this processing to complete – unlike in the other storage mechanisms.
Referenced File From Item
:
The frame’s data is held in a frame of a different item. The frame stores the PDUID of the other item whose data is being referenced (latest instance), and the name of the frame in this other item that contains the data. When the frame is accessed via a View command, Cradle opens the other item using its PDUID and copies the data from the referenced frame into a temporary file. This mechanism allows data in one item to reference data in another item, sharing the data between them.
Cradle URLs
Cradle URLs are URLs that can start a Cradle WorkBench client and either open an item or run a query. The action specified in a Cradle URL is executed by the c_url utility shipped in the Cradle clients. It can be run from a command line, an application, or a web browser that has been told about Cradle URLs (an option when Cradle clients are installed).
Cradle URLs are a way for another application to interface to Cradle. The other application can store Cradle URLs as, in effect, pointers to items in the Cradle database. When the user wants to access the Cradle item, the external application can either run c_url on the specified Cradle URL, or route it through a web browser that, in turn, will launch c_url.
Cradle URI Scheme
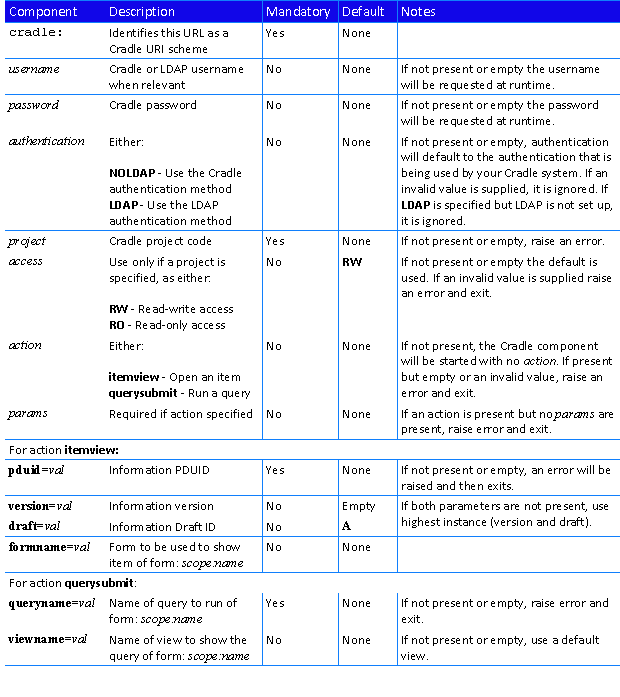
A URI scheme defines the structure of a URL. The Cradle URI scheme is:
by specifying a Cradle URL with the PDUID and instance details of the item to be opened.
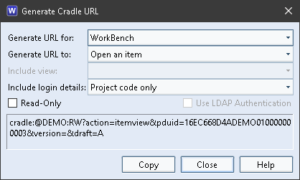
Creating Cradle URLs
Cradle URLs can be created from the Tools tab WorkBench UI or any web UI. Once an item is selected:
Create Cradle URL
The Cradle URL shown in the dialog can be copied and pasted:
Into another application to provide a link to the selected item in Cradle
Into the c_url utility to execute the action in the URL
Into a web browser that understands the Cradle scheme, when it will launch the c_url utility to perform the requested action
API
Cradle has an Application Programming Interface (API) that supports both C/C++ and VB.NET. You can create any number of applications using the API. All of these applications will connect to the CDS in the same way as any non-web-based Cradle client supplied by 3SL (such as WorkBench or Document Publisher). Each of your applications can service one or many users. You need one API/WSI connection licence for every application that you want to concurrently connect to Cradle.
The API contains many routines. Collectively these routines provide facilities to create, read, update and delete both items and the cross references between them. The main data type for items is CAPI_ITEM_T which has components for both item identities and PDUIDs. The main data type for cross references is CAPI_XREF_T which contains the details of the cross reference but not the items that it connects. This is because cross references are not retrieved by themselves, rather the API returns a list of linked items each of which is a structure containing the CAPI_ITEM_T for the linked item and the CAPI_XREF_T for the cross reference by which it is linked. As such, the “from” and “to” items for a cross reference are implicit in the data structures.
A PDUID can be used to open an existing item using CAPI_Item_Open().
WSI
Cradle has a Web Services Interface (WSI) that supports a RESTful message protocol. You can create any number of applications using the WSI. All of these applications will connect to the Cradle Web Server (CWS) in the same way as any web-based Cradle client supplied by 3SL. Each of your applications can service one or many users. You need one API/WSI connection licence for every application that you want to concurrently connect to Cradle. Each of these connections can either be session-based or it can use message-by-message connections.
The WSI contains many operations. Collectively, these operations provide facilities to create, read, update and delete both items and the cross references between items. The data sent and received in these operations is packaged in JSON. These JSON packets contain full details of items and cross references and include both item identities and PDUIDs.
The WSI predominately uses PDUIDs as a means to specify items of information, and for links between items. For example using the curl command to send a HTTP message to a Cradle WSI session whose details are in the file cookies.txt to the CWS running on port 8015 at server myserver to get the contents of a database item into a local JSON file:
curl -X GET -b cookies.txt “http://myserver:8015/rest/projects/DEMO/items/16EC668D4ADEMO010000000907?fields=all” > myItem.json
and to update the same item in Cradle with new information added into the same local JSON file:
curl -X PUT -b cookies.txt “http://myserver:8015/rest/projects/DEMO/items/16EC668D4ADEMO010000000907” -d @myItem.json