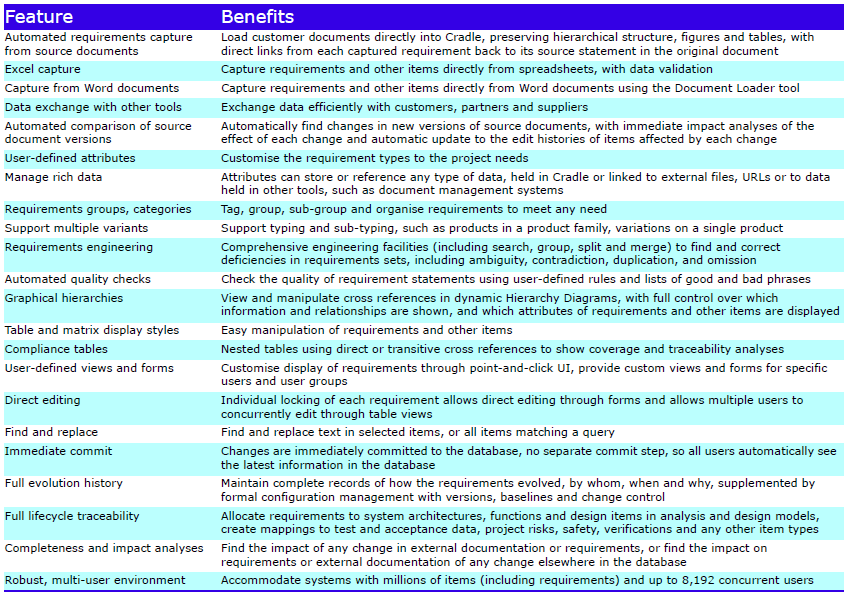
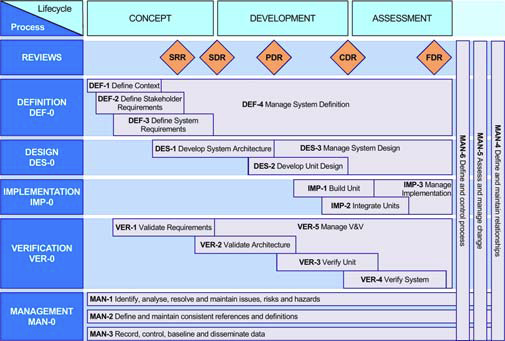
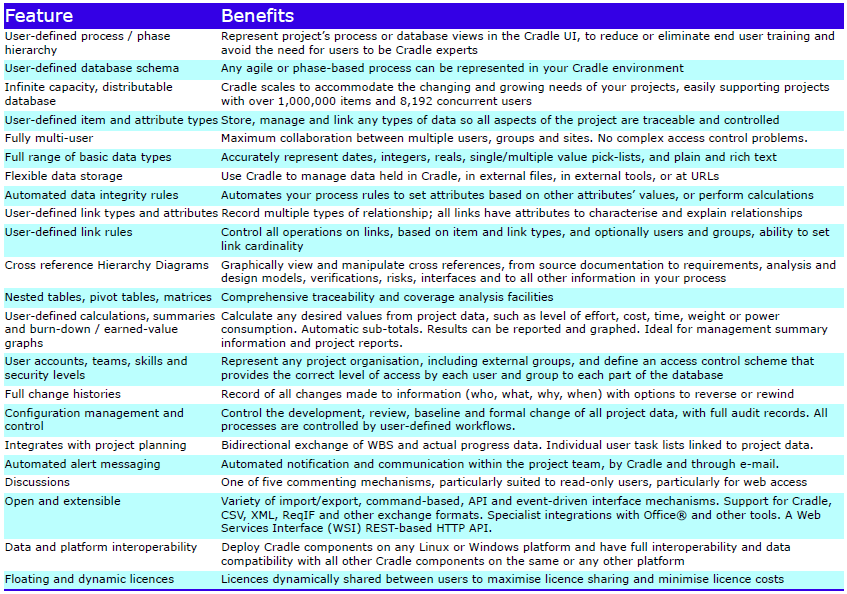
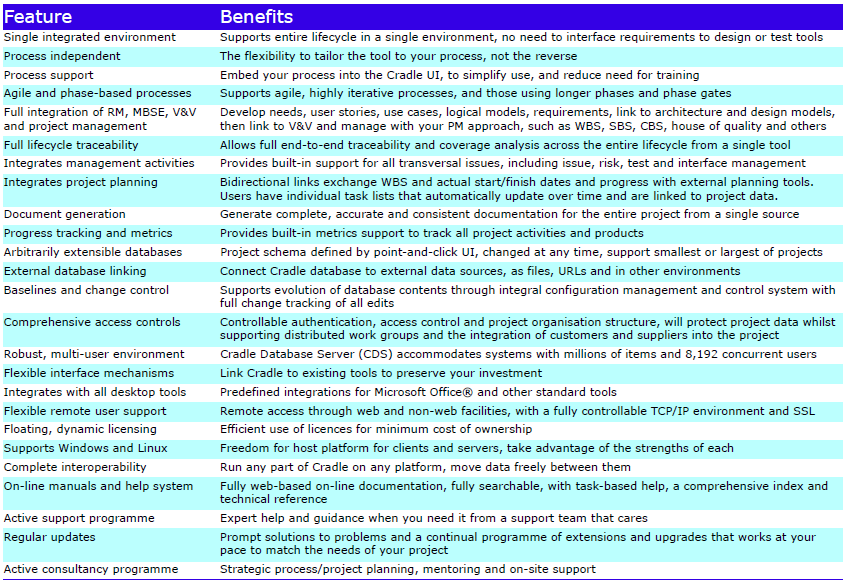
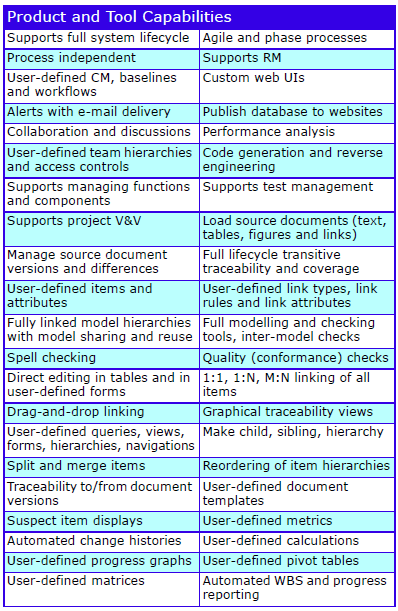
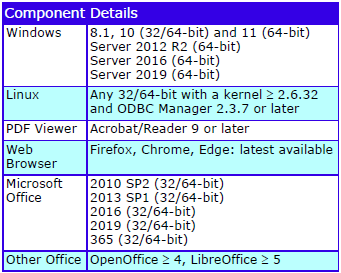
The Cradle REQ module provides a complete requirements capture and engineering solution with built-in CM. It can manage needs, risks, products, features, tests, validations and any other data. It is easily applied to both agile and phase-based processes.
REQ Requirements Management Module
Requirements management is part of every agile and phase process. Stakeholder needs are captured, analysed and engineered. Changes are tracked in a CM system. All needs will be linked to design, build, test and acceptance information. In agile, this is in every sprint. In phase-based processes, it is less frequent. But the techniques are the same, and the same tool needs apply that only Cradle provides:
Requirement types can be defined (user, business, system, product, functional or non-functional), user stories and use cases. Link to codes, standards, regulations, knowledge or assumptions. You define other item types to be managed, such as functions, issues, tests, risks, SBS, PBS, WBS or defects. Attributes in these items are controlled, how they will be linked to each other, and their workflows.
Item Attributes
Items have user-definable attributes, each storing or linking to up to 1 TByte of data. Attribute types are user-defined, including dates, numbers, plain and rich text, single or multi-value lists, Office and other documents, and calculations.
The text in requirements, tests, verifications and other items can be quality checked against project-specific rules.
Items can be in hierarchies, groups and many:many relationships. You can create projects using a common library. Product ranges, models, variants and builds are supported. Items can be shared and reused in any of these structures.
Capturing Items
Items can be captured from external documents by Document Loader. It reproduces the document structure in a hierarchy of items. Each item is linked to its origin in the document. Figures are loaded automatically. Tables can be captured into items, images, Word objects or rich text.
Document Loader finds differences in new versions of documents. Loading the new version will update items and their links. Coverage analysis between documents and database items are provided.
Full version management of source documents is provided. Regression to previous versions is supported, with reversal of all changes.
Requirements and other items can be loaded from Word, Excel or other tools using plug-ins, data exchange or direct interfaces.
Analyses
Coverage, traceability and impact analyses are easily run, then viewed as trees, lists, tables, matrices, or in dynamic Hierarchy Diagrams with user-defined attributes. Items can be filtered, sorted, split and merged. All changes to items can be logged. Users can be alerted to changes by Cradle, email or both.
Discussions
Users collaborate by adding discussions to items and adding threads to items and adding threads of comments to these discussions.
Reviews
Once stable, items can be progressed through a series of formal reviews that log comments from all reviewers. You define the workflows. Once in a baseline, items can be subject to formal change control using change request (proposals) and change tasks (actions). You can view the database as it was in any previous baseline.
Multiple generations of requirements can be maintained and compared. Multiple sets of variants can be managed to reflect different products in a common family.
Items can be progressed within their lifecycles. The lifecycle of an item represents the series of stages that it can pass through between being created and reaching a final, rest, condition.
User-defined tree, table and matrix views can be defined from a point-and-click UI to show traceability, coverage and compliance. This includes RTMs, VCRMs and PVMs.
Linking Items
Cradle provides transitive cross referencing, in which it follows chains of multiple links between indirectly linked items, so you can see cross-lifecycle traceability in one step. For example, you can view user requirements to tests, where Cradle transparently follows intermediate links via system requirements, functions, architecture components and so on.
Requirements can be linked to test data, safety and other critical issues, risks or any project data. When used with the Cradle-SYS module, user stories and requirements can be linked to functional, behavioural, UML, analysis, architecture and design models organised into any number of model hierarchies in both analysis and design domains.
Publish Information
All information can be published in user-defined reports and formal documents.
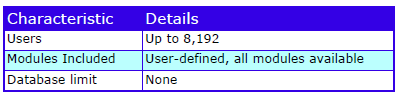
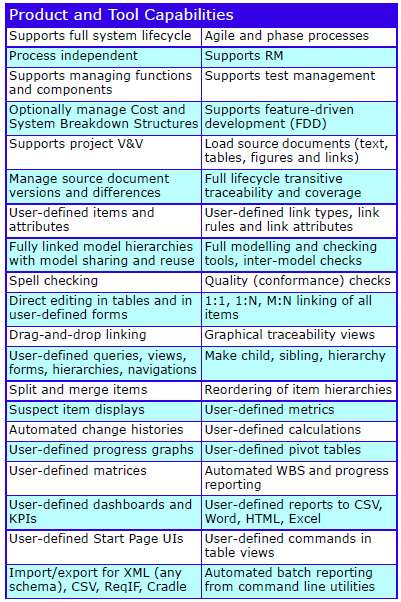
Feature Summary
Feature Summary – REQ
Please contact 3SL for further information about adding a Cradle REQ module to your existing system.
The Cradle PDM module provides the infrastructure for all other Cradle modules. Its scalability and flexibility create an industrial strength, proven, shared data environment for even the largest projects:
Cradle PDM Module
Databases
Cradle supports any number of databases, each with its own schema, CM system and users. Each database supports many projects. Use the Project Manager tool to organise this environment by user-defined criteria, for example as hierarchies.
Each database stores any number of items, of any number of types (requirements, risks, classes, user stories, functions) defined by a UI. Items have any number of attributes, each of a user-defined type, that manage up to 1 TByte of any type of data, held in Cradle, or referenced in external files, URLs or another tool or environment.
Calculations
User-defined calculations are supported in all parts of Cradle and can be displayed as graphs, in views and user-defined reports. User-defined rules can be applied to automatically set attribute values or perform calculations, to maintain the integrity within and between items.
Cross References
Items can be cross referenced, with optional user-defined link types and groups. Links have user-defined attributes to justify, parametrise, explain or characterise them. You control which links are used to navigate or report traceability, based on link type or group, direction and link attribute values. Links are both direct and indirect, for full lifecycle traceability, impact and coverage analyses.
Process Tailored Environment
You use start pages and a phase hierarchy to build an environment tailored to your process. End users only need to be trained in your interface, reducing training time and costs:
Start pages are text and graphics controls that perform your choice of operations simply and easily
The phase hierarchy shows the process as a hierarchy in which an agile or phase activity, task, sprint, report or document is run by a mouse click. Different parts of the phase hierarchy can be shown to each user or stakeholder group.
Traceability and coverage views are available as trees, nested and pivot tables, matrices and Hierarchy Diagrams. Unique transitive links give traceability across the full system lifecycle.
Configuration Management
Items evolve through versions that are managed in baselines and controlled by a built-in CM system, with mechanisms for review, baseline and version control, full change control, and audit trails.
Cradle can track all changes. Edits can be reversed selectively or by group. Items can be compared across edits and in baselines. Edits can raise alerts to users, and mark related items as suspect. All edits are permanently available, for change logs.
Adaptations
Cradle provides adaptations to allow variants of items. This mechanism is ideal for databases that contain a library of standard items and projects that use the library, and contribute to it.
Access Controls
Access controls apply to all items based on user roles, privileges, security clearances and skills. Users can be grouped in a hierarchy of teams, to create any access control scheme, such as for customers, subcontractors and IV&V. The creation and manipulation of links can be controlled, by item or user.
Cradle is multi-user. It locks information at item level, with automatic database commit after an edit. This maximises users’ interaction with the database and guarantees all data s up-to-date.
Alerts
Cradle’s alert mechanism sends messages by email (SMTP or IMAP), Cradle or both. Alerts can be selectively enabled and disabled. Alerts track events on items, including edit, review and formal change.
Discussions
The Cradle discussion mechanism allows even read-only users to add comments to items. Four other commenting mechanisms are provided.
Project Planning
Cradle can manage project plans and WBS. User task lists are maintained. WBS structures and progress data can be exchanged bidirectionally with external PM tools. Cradle can generate burn-down and earned-value graphs on any user-defined criterion to monitor progress.
API
Cradle is open and extensible. It provides multiple import/export formats, an API, a user-definable event-driven command interface, interfaces with other tools and bidirectional interfaces to Microsoft Office.
Query and Report Data
Cradle provides uniquely powerful data query and visualisation facilities. Each user’s environment can be tailored by defining custom queries, views, forms, navigations, matrices, reports and other facilities. All customisations have a scope, to be specific to the end user, or shared with other users of the same type (such as all customers or all managers), the user’s team, the entire project, or all projects.
Any desired compliance, coverage or traceability report can be created quickly/easily using Cradle’s queries, multi-row views/nested table view, and saved for later use.
Licensing
Cradle has floating, dynamic licensing and low cost read-only users. Open and named user licences are available. Everything described here is free of charge.
Licences, databases and schemas are interchangeable across Linux and Windows 8.1, 10, 11, Server 2012 R2, 2016 and 2019.
Optional support for Oracle and MySQL.
Feature Summary
Feature Summary – PDM
Please contact 3SL for further information about Cradle PDM licences.
This is the second in a short series of posts that explain Project Database Unique IDs (PDUIDs). This post explains how to view PDUIDs and their components. Later posts will explain:
How they can be used in operations in Cradle tools, API and WSI
How PDUIDs can be changed or preserved when information is moved between databases
Viewing PDUIDs
You can show PDUIDs and their parts anywhere that you can show any other item attributes, especially in views and forms. Use views to control how the results of queries will be shown. You use forms to show single items. In both cases, you decide which of the items’ attributes to show. You can show either PDUIDs or any of their parts. All of these values will be displayed read-only.
Views
A view specifies which of an item’s attributes will be shown, and the order and position of the values of these attributes.
Display Styles
You can display a view in one of four display styles:
List
:
Lists show each item in a row of read-only text. Lists cannot contain colour, images or linked items. You use a list to show the maximum number of items on screen at the same time.
Table
:
Each item is shown in one or more rows, each of one or more columns, which creates a grid of display cells. Each of these cells can contain text or graphics. You can specify colour and text styles for the cells. The cells also allow linked items to be shown. Some cells are editable. You can also create display menus of user-defined commands. Table style is the most common display style.
Document
:
This is the same as Table style except that row and column borders are not shown and different font sizes are used to display the first row of each item. The size of the text is based on the identity or other alphanumeric attribute, so that the effect is similar to the headings and subheadings of text in a document.
Tree
:
Each item is displayed as a node in a tree and a single row of values similar to List style. You can control the format of the tree nodes by a separate view. These tree nodes can be expanded and collapsed to show or hide sets of linked items.
Views are Tables
Most views have one row of cells, each containing one of the item’s attributes. So if a query returns 200 items, then the view will contain 200 rows, one per item. Items can be shown over more than one row. For example, if the same query is displayed with a view that uses 3 rows to show each item, then the result will be a table with 600 rows of the form:
Items as Table Rows in a View
View Cells
Each cell in a view can contain fixed text, an attribute, linked items, or several attributes combined into a single value with some optional separating characters.
PDUIDs in Views
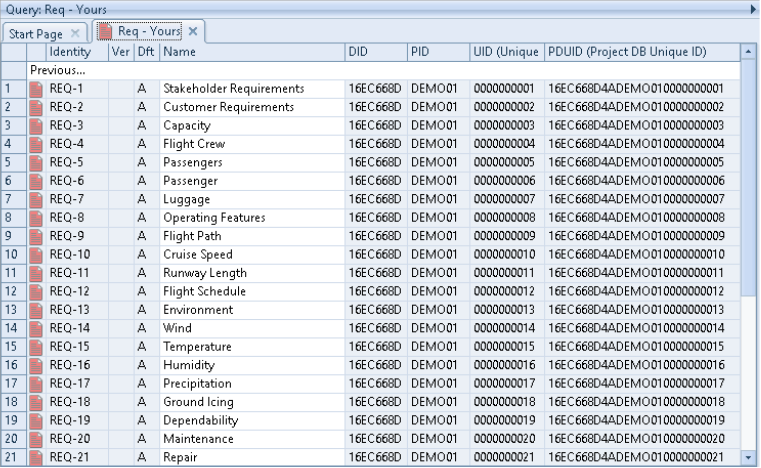
All of the components of PDUIDs are available to be shown in cells in a view. For example:
DID PID UID and PDUID in View in Table Style
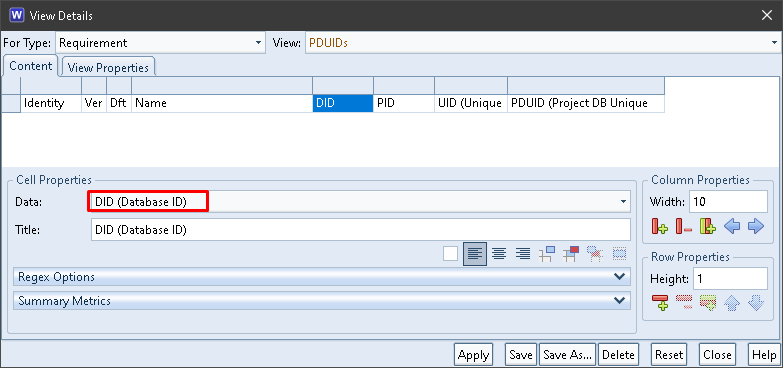
The DID column contains the Database ID component from the items’ PDUIDs:
DID in a View
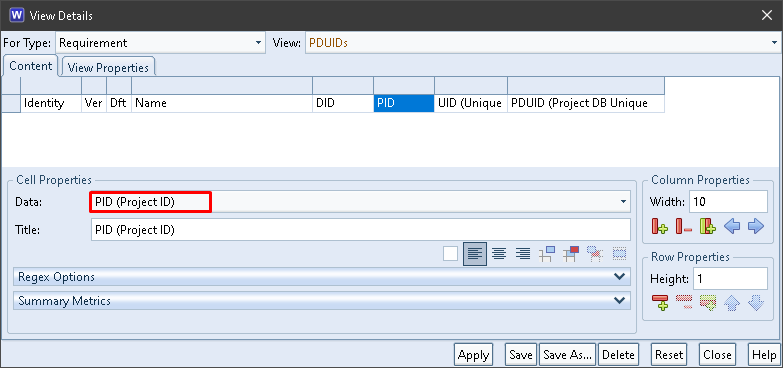
The PID column contains the Project ID component from the items’ PDUIDs:
PID in a View
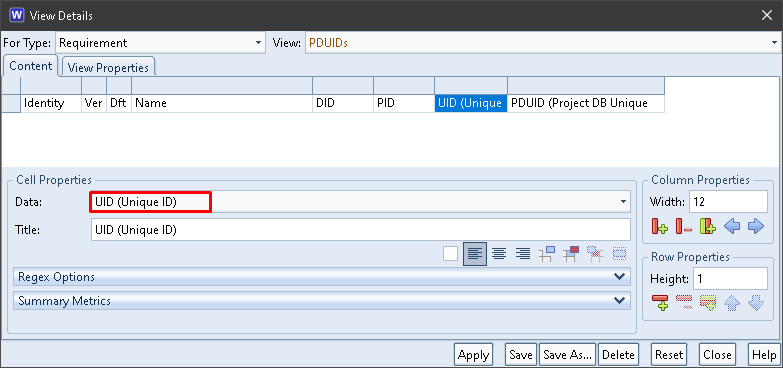
The UID column contains the Unique ID component from the items’ PDUIDs:
UID in a View
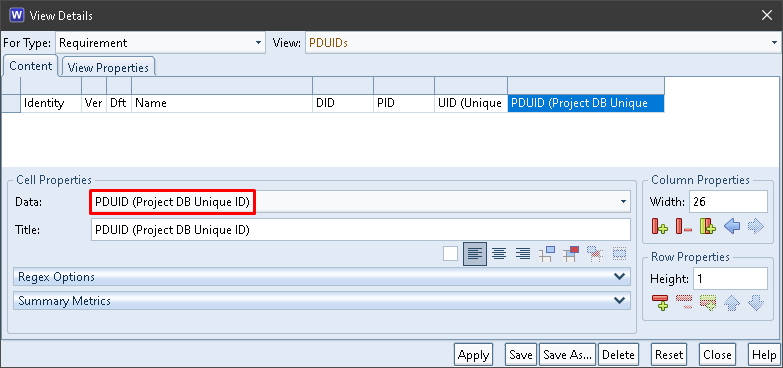
The PDUID column contains the items’ entire PDUIDs:
PDUID in a View
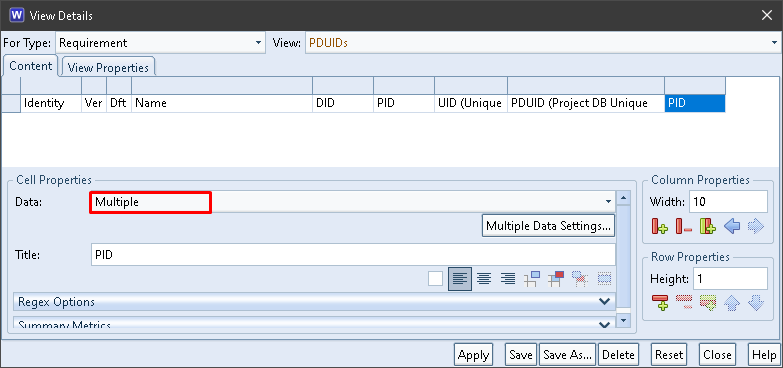
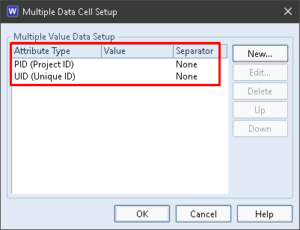
There is no component to show the items’ Project Unique IDs (PUIDs). The PUID is the combination of the PID and UID, so we can easily output this in a view cell using the data type Multiple and concatenating these attributes with no separators:
PUID in a ViewPUID Component Attributes
All of these cells will be read-only in all display styles since PDUIDs are not user-modifiable attributes.
Forms
A form is a collection of fields, grouped into rows and columns, that display information for a single item. You can arrange the fields in a form in any way that you wish, to create any layout of information that you wish. Regions of forms can be made collapsible inside panels. Each field in a form can contain fixed text, an attribute or a collection of linked items. If an attribute is editable, then the form will allow it to be edited, subject to the user’s access rights to the item and that specific attribute. In addition, a field can be set to prevent editing of an attribute that would otherwise be editable.
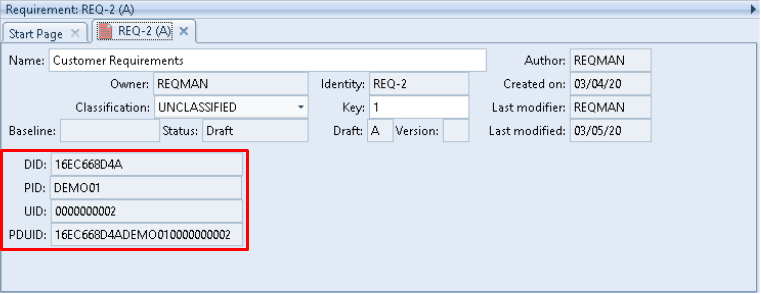
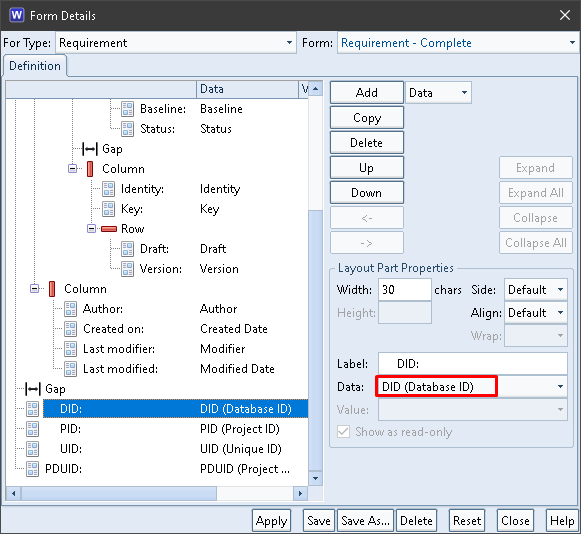
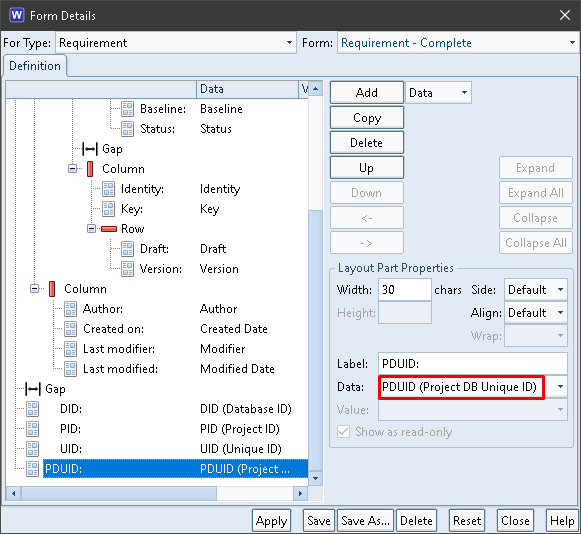
All of the components of PDUIDs are available to be shown in fields in a form. For example:
PDUID and Components in a Form
The DID field contains the Database ID component from the item’s PDUID:
DID in a Form
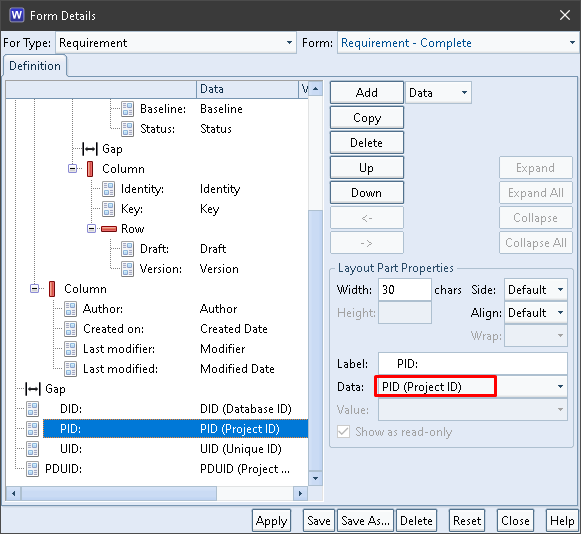
The PID field contains the Project ID component from the item’s PDUID:
PID in a Form
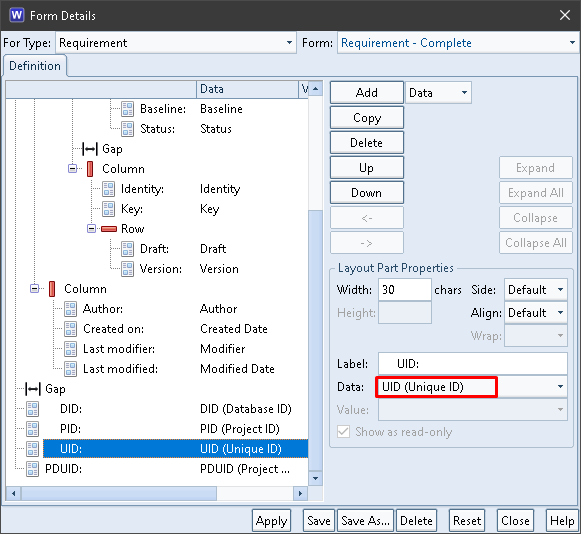
The UID field contains the Unique ID component from the item’s PDUID:
Cradle is an integrated requirements management and systems engineering environment with the features, flexibility and scalability for the full lifecycle of today’s complex agile and phase-based projects.
Overview of Cradle Modules
From concept to creation, from Cradle to grave.
Cradle is unique. It provides the tools and features to create and manage all your data, at all stages in your systems development, and at all levels. By managing all the data in one place, only Cradle can provide traceability across the entire lifecycle in one tool. Without Cradle, you have to assemble many products from many vendors, and you will still not have the full traceability that Cradle can provide.
What does Cradle Provide?
Cradle provides full requirements management, analysis, design, architecture and performance modelling, test, risk and interface management and metrics in one product. You can use all of these facilities, or combine Cradle with tools from other vendors. If you have such tools then Cradle will link to them, extending their scope from a part of the system lifecycle to all of it.
Cradle is multi-user, multi-project, distributed, open and extensible. It links to your existing desktop tools to create a tailored environment to suit your process.
Cradle provides built-in issue, risk and interface management. It supports comparative trade studies and analyses. Cradle provides a built-in configuration management and control system with baselines, version control, change histories and formal change control. It bidirectionally links a WBS and progress reporting to your project planning tool. With these capabilities, Cradle removes the need for you to try to connect risk, CM or change tracking tools to your systems engineering. Cradle provides everything you need, integrated and ready to use.
Access Control and Authentication
Cradle has customisable, hierarchical, access control facilities and integrates with your authentication, access control and security mechanisms including firewalls, LDAP and SSL. Cradle provides user-definable views of project data, tailored to each stakeholder group. With customisable navigation, review and entry tools and tailored web UIs, Cradle shows each user the data that they want to see, in the way that they want to see it.
Cradle Databases
Projects use user-defined, arbitrarily extensible databases, linked to external files, URL resources and data in external repositories. Each database is configuration controlled, with change histories, baselines, versions and variants, managed by configurable change requests and change tasks.
Cradle Access
Cradle supports off-line and remote access from geographically separate groups. Internet and VPN access is provided, with full support for project and company firewalls and DMZs.
It connects dispersed teams together, with tailorable discussions, alerts and e-mail.
Cradle Modules Overview
Cradle is modular, using floating licences to share resources dynamically across the project. The Cradle modules overview is:
Cradle-PDM provides a project infrastructure, from access control and user accounts, through a user-defined schema, phase hierarchy, team hierarchy and access controls to configuration management and open external interfaces.
Cradle-REQ provides requirements management from external source documents to baselined, engineered requirements linked to the rest of the system lifecycle. It allows you to define and manage user stories, validations, test cases, and any other types of information for all of your process.
Cradle-MET provides user-definable metrics to gather and analyse statistics from project data.
Cradle-SYS is a flexible analysis and design modelling environment. It allows any number of models to be built and grouped into model hierarchies in distinct analysis and design domains. Models are fully cross referenced to requirements and all other information. SysML is also supported.
Cradle-DASH provides user-definable Key Performance Indicators (KPIs) calculated from live project data in user-defined dashboards shown as tables or dials.
Cradle-PERF provides performance assessment, budget apportionment and data aggregation facilities for design models at any level in a system development.
Cradle-SWE provides code generation and reverse engineering for C, Ada and Pascal, to synchronise design and source code.
Cradle-DOC provides user-defined project document generation and a formal document register of project deliverables.
Cradle-WEBP provides web publishing of project data to static, hyperlinked, websites for external stakeholders.
Cradle-WEBA allows read-only and read-write access to project data through multiple, user-defined, web UIs that are tailored to each stakeholder group. It also provides external access to Cradle items through URLs.
Cradle-RISK provides ability to open and edit items of the mapped item type for risks. Also allows you to create and open risk profile graphs.
Cradle-TEST provides ability to execute test plans and create/edit test information, e.g. test cases, test results and test runs.
Feature Summary
Feature Summary – Overview
Please contact 3SL for further information about adding any of the Cradle modules to your existing system.
Collaborative Model Based Systems Engineering across the Systems Lifecycle
Complete Application Lifecycle Management (ALM), Model Based Systems Engineering (MBSE) and documentation solution for the entire project lifecycle, fully user-definable and applicable to all agile and phase based processes.
Supports the full systems development lifecycle at system, subsystem and lower levels
Integrates in one product features normally spread across separate tools from different vendors
Completely user-definable and user-extensible with point-and-click UIs
Manage any information, including requirements, risks, interfaces, tests and verifications
Scalable to millions of items of information
Full traceability of data from external sources and version management of source documents
Full traceability and coverage analyses
User-definable views of data including tables, trees, documents, matrices, diagrams and graphs
User-defined metrics and management dashboards
Cradle Enterprise is a complete multi-user solution to manage, trace and document all the data for your agile and phase-based projects.
Capture and Track Information
Capture information from external documents and tools, and track changes in these sources. You can build new sets of requirements, analysis, architecture and design models, tests or verifications, and link them to the source data and to each other. Check the consistency and quality of this information, and prove the integrity of the models and other data with bi-directional coverage and traceability analyses.
Customers’ confidence can be raised with proof that your work satisfies its sources and constraints, and will meet their needs.
Easily track progress with metrics and KPIs and link to your WBS and actual progress to your project planning tools.
Create Databases and Information
Create any number of databases, each with a schema and multiple projects that contain any number of items of any number of user-defined item types. Each item has any number of attributes with up to 1TByte of data, held in Cradle, or referenced in files, URLs or other tools.
All items can be linked with user-defined types of cross reference. The links have attributes to justify, explain or parametise them. Links are direct and indirect, for full lifecycle traceability, impact and coverage analyses.
External documents can be loaded into hierarchies of items. Every item in Cradle is linked to its source in a document. Changes in new document versions are automatically found and the database updated. You can prove the integrity of all source data to your customers with a range of detailed coverage analyses of their documents.
Items can be linear, hierarchical and in many-to-many relationships. Items can be split, merged and reordered. All information can be shared and reused. Cradle can support product ranges, models, variants and builds, and generate comparative analyses between them as tables, pivot tables and matrices.
Create any number of analysis, logical, process, architecture or design models in SysML, UML, SASD, IDEF, ADARTS and other notations. Optionally group models in hierarchies and link elements of all models to requirements, SBS, issues, test cases and all other information.
Track and View Information
Cradle tracks all edits to every requirement, test case, verification and all other information that you want it to hold. Edits can be reversed selectively or by group. Full or partial change logs are readily available.
Control the work with team hierarchies, roles and access controls. Review items with discussions, user-defined workflows and built-in CM with baselines, full version control and formal change management.
You define how information is viewed and reported in any number of views, shown as nested tables, trees, matrices, pivot tables and as diagrams.
Generate versions of documents such as a URD, SRD, IRS, SDS and SSDS to match your or your client’s formats with user-defined templates and detailed traceability of which items were published in each document issue.
Manage Projects
Manage your projects with:
Metrics, user-defined calculations of items’ values
Bi-directional links to Project, including user task lists and actual progress reporting
Cradle is open. It supports many import/export formats, has several interface mechanisms to link to other tools, and connects to Microsoft Office components Word, Excel, PowerPoint, Visio and Project.
Cradle is simple to customise and use through point-and-click UIs.
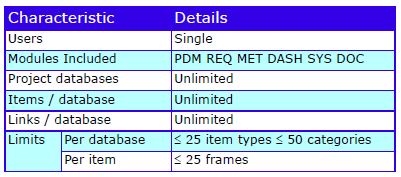
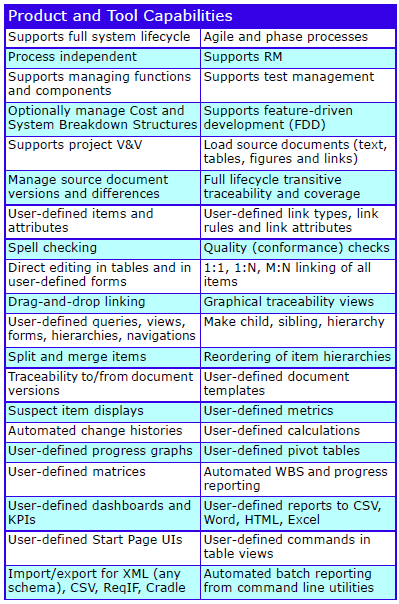
Major Features
The major features are:
Cradle Enterprise Features
Supported Platforms
The supported platforms are:
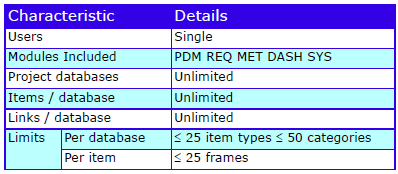
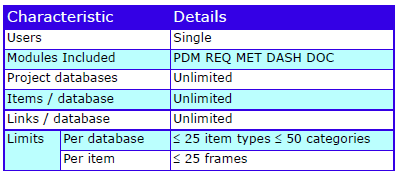
Characteristics
The characteristics are:
Cradle Enterprise Characteristics
Cradle Enterprise is part of the Cradle product range that includes low cost, single-user tools.
Model Based Systems Engineering across the Systems Lifecycle
Complete Application Lifecycle Management (ALM) and Model-Based Systems Engineering (MBSE) and documentation solution for the entire project lifecycle, fully user-definable and applicable to all agile and phase based processes.
Supports the full systems development lifecycle at system, subsystem and lower levels
Integrates in one product features normally spread across separate tools from different vendors
Completely user-definable and user-extensible with point-and-click UIs
Manage any information, including requirements, models, risks, interfaces, tests and verifications
Scalable to millions of items of information
Full traceability of data to source and generated documents with complete version management
Full traceability and coverage analyses
User-definable views of data including tables, trees, documents, matrices, diagrams and graphs
User-defined metrics and management dashboards
Cradle-SE Pro is a complete solution to manage, trace and document all the data for your agile and phase-based projects.
Capture and Track Information
Capture information from external documents and tools, and track changes in these sources. You can build new sets of requirements, analysis, architecture and design models, tests or verifications, and link them to the source data and to each other. Check the consistency and quality of this information, and prove the integrity of the models and other data with bi-directional coverage and traceability analyses.
Customers’ confidence can be raised with proof that your work satisfies its sources and constraints, and will meet their needs.
Easily track progress with metrics and KPIs and link to your WBS and actual progress to your project planning tools.
Create Databases and Information
Create any number of databases, each with a schema and multiple projects that contain any number of items of any number of user-defined item types. Each item has any number of attributes with up to 1TByte of data, held in Cradle, or referenced in files, URLs or other tools.
All items can be linked with user-defined types of cross reference. The links have attributes to justify, explain or parametise them. Links are direct and indirect, for full lifecycle traceability, impact and coverage analyses.
External documents can be loaded into hierarchies of items. Every item in Cradle is linked to its source in a document. Changes in new document versions are automatically found and the database updated. You can prove the integrity of all source data to your customers with a range of detailed coverage analyses of their documents.
Items can be linear, hierarchical and in many-to-many relationships. Items can be split, merged and reordered. All information can be shared and reused. Cradle can support product ranges, models, variants and builds, and generate comparative analyses between them as tables, pivot tables and matrices.
Create any number of analysis, architecture, logical, process or design models using UML, SASD, IDEF, ADARTS, SysML and other notations. Group models in hierarchies and link all elements of all models to requirements, SBS, issues, test cases and all other information.
Track and View Information
Cradle tracks all edits to every requirement, test case, verification and all other information that you want it to hold. Edits can be reversed selectively or by group. Full or partial change logs are readily available.
You define how information is viewed and reported in any number of views, shown as nested tables, trees, matrices, pivot tables and as diagrams.
Generate versions of documents such as URD, SRD, IRS, SDS and SSDS to match your or your client’s formats with user-defined templates and detailed traceability of which items were published in each document issue.
Manage Projects
Manage your projects with:
Metrics, user-defined calculations of items’ values
Bi-directional links to Project, including user task lists and actual progress reporting
Cradle is open. It supports many import/export formats, has several interface mechanisms to link to other tools, and connects to Microsoft Office components Word, Excel, PowerPoint, Visio and Project.
Cradle is simple to customise and use. You do not need to learn a scripting language or become a programmer to tailor it to your process. After every change to your schema, Cradle will automatically update collections of queries, views and other definitions that make you productive immediately.
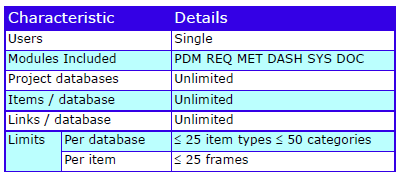
Major Features
The major features are:
Cradle-SE Pro Features
Supported Platforms
The supported platforms are:
Characteristics
The characteristics are:
Cradle-SE Pro Characteristics
Cradle-SE Pro is part of the Cradle product range. The full, multi-user, product is Cradle Enterprise.
A Cradle system can contain any number of databases. For the best performance, we recommend that databases are stored on disks connected to the machine that runs your Cradle Database Server (CDS). But, this may not be possible.
For example:
The local system may not have enough disk space available
The information in the database may be classified and must be stored separately
Here each database will be stored on a remote filesystem that must be referenced by a pathname so the CDS can work with it.
Remote Linux Filesystems
On Linux, a remote filesystem is mounted as a pathname. The CDS works through this pathname to access the remote filesystem. Remote filesystems include NFS (network file system) and others.
3SL does not recommend the use of CIFS (Common Internet File System) filesystems. We have seen several Linux systems that use CIFS to mount remote Windows filesystems. Sadly all these CIFS filesystems have provided very poor performance to the Linux server.
For NFS mounts, we suggest that you examine block sizes of 4K or more and consider nosuid mounts.
Remote Windows Filesystems
We are sure you are familiar with drive letters such as G: or H: that are the connection point to filesystems on remote systems.
For example, a filesystem disk1 on server myfileserver1 can be mounted as the X: drive. You can navigate to a pathname on X: such as:
X:\Cradle Databases\ABCD
You cannot use drive letters in the pathname to create a Cradle database on a remote drive. Drive letters are specific to a Windows profile and are created only when that profile is active.
So, please use UNC pathnames to refer to Cradle databases on remote drives. UNC pathnames are of the form:
\\servername\path
So in the above example, the pathname to the ABCD database would be:
\\myfileserver1\disk1\Cradle Databases\ABCD
Access to Remote Windows Databases
You must ensure that the access rights to remote directories will allow the CDS to search all directories inside the database and give RW access to all of the database files. Please note that the CDS runs as the local SYSTEM user on the machine where it is run. So it is this user who must have search, read and write access on the remote filesystem.
If you wish, you can control the user who will run the CDS. To do this iteratively (you may need to have Administrator rights depending on your system):
Open Task Manager and in the Services tab, stop the Cradle Services Manager
Open Windows Explorer
Navigate into your Cradle system and look in the folder bin\exe\windows
Press SHIFT and right-click on the CDS executable: crsvr.exe and choose Run As and enter the username and password that you want the CDS to run as
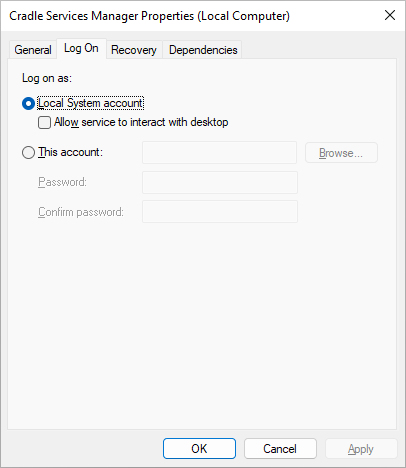
If you want to permanently change how the CDS runs, then (you may need to have Administrator rights on your system):
Open services.msc, the MMC (Microsoft Management Console) or Services Control Manager (depending on your version of Windows) to see all services and stop the Cradle Services Manager
Select the Cradle Services Manager, right click and choose Properties
Select Log On in the dialog and specify the user that you want the CDS to run as and the password for this account:
Click OK to close the dialog
Start the service and then close the list of services
This is the first in a short series of posts that explain Project Database Unique IDs (PDUIDs). This post explains the purpose of PDUIDs and their structure. Later posts will explain:
How PDUIDs can be viewed
How they can be used in operations in Cradle tools, API and WSI
How PDUIDs can be changed or preserved when information is moved between databases
Identifying Information
Each piece of information must be distinguishable from all other pieces of information so we can be sure we have found what we were searching for. We do this by marking each piece of information in a unique way.
For information in databases, the markings are unique values called keys or identities. A piece of information can have multiple identities, each for a different purpose. For example, although a company’s payroll system is likely to identify each person by a unique Employee ID, each person’s details will also include their governmental tax ID (such as a National Insurance number, a Unique Taxpayer Reference, a Sozialversicherungsnummer or a Social Security Number). This tax ID will also be unique and so could also be used as an identity for that person’s information.
Cradle has two forms of identity, item identities and Project Database Unique IDs (PDUIDs).
Database and Host Identities
Every Cradle system has a Cradle Database Server (CDS) to manage the information in its databases. The CDS is locked to a Host ID, the last 8 digits of the MAC address of the host’s primary network interface.
All databases in a Cradle system share a common Database ID (DID), a 10-character ID of the form:
Platform ID Host ID
where:
Platform ID
:
CDS’s platform, 02 for Windows or 17 for Linux (other values are for obsolete platforms such as Domain/OS, SunOS, Solaris, HP-UX, Ultrix, SCO, OSF/1 and VMS)
Host ID
:
CDS’s host ID, also used in the system’s Security Code
For example: 1750D4FA4C
The role of a DID is to differentiate information in a database managed by one CDS from information in databases managed by any other CDS, even if all other particulars of the information are the same, such as they are the same item of the same item type in the same project in these disparate Cradle systems.
A common example is when organisations send information to each other, such as customers and suppliers. This creates two copies, or instances, of each piece of information. The databases’ DIDs differentiate the instances held by the customer and suppliers. This is important because:
An organisation cannot know if other organisations have changed information
It is important to know which organisations hold each piece of information and which pieces of information each organisation holds
It may be appropriate to designate one instance as primary so its content is authoritative and other instances are secondary
Project Identities
A Cradle system can manage many databases. Each database is used for one or more projects. Each database has a unique 4 character Project Code that is used at login to specify which database is to be accessed.
Separately, a Project ID (PID) can be specified when a database is created using the Project Manager tool, or c_prj utility. This is a 6-character string and is typically similar to the Project Code. It defaults to six underscores:
______
The Project ID can be used to label a database. It can be helpful if databases are related, for example as successive missions in a programme or separate vessels in a class of ships, when related Project IDs could be used:
ARTEM01
ARTEM02
ARTEM03
Role of Project IDs
It is likely that what might appear to be the same information could exist in two or more databases. This could be intentional and helpful, or it could be unhelpful and inconvenient. The fundamental role of a PID is to differentiate between databases:
In the most common scenario, an organisation uses its standard process in several projects. These projects’ databases will contain the same types of information, such as hierarchies of needs and user requirements, and the same structuring and numbering conventions. It is quite likely that the databases will contain items with the same hierarchical numbers and, for groups and sub-groups, the same names:
1 Context
1.1 Purpose
1.2 Roles
1.2.1
2 Stakeholders
2.1 Purchasers
2.2 Operators
Here it is inconvenient that multiple requirement 1.2.1s exist in the databases, each with unrelated contents. Viewing requirement 1.2.1 in isolation could give an incorrect understanding by interpreting it as part of one project when it is actually part of another project.
In an alternate scenario, two or more databases could be logically related. Indeed one database may be an extension of another, or an evolution of it at a later stage in the project. In this case, viewing information in isolation would not show which database it came from and could also create an incorrect understanding.
In both scenarios, including a PID would differentiate the content of each database from the others.
Item Identities
Cradle databases contain different types of information. The basic unit of information in a Cradle database is the item. Every item has an associated item type that defines the type of information it contains. Projects can create their own item types in the schema that describes the database’s structure and rules. For example:
HLURs, high level user requirements
SRs, system requirements
TEST CASE, description of a test to be run with the steps to perform and their possible outcomes
Collectively the items of such user-defined item types are called system notes.
Identities and Instances
Every item has an identity to uniquely identify it amongst other items. An identity is the combination of the values of several attributes.
Items evolve over time. Projects will usually keep copies of items at different stages in their evolution. Cradle has the concept of instances of an item. Instances are copies of items as they were at some time in the past, typically in previous baselines. In MBSE (model based systems engineering) users can create multiple instances of diagrams and specifications as alternative analyses or designs. These alternatives co-exist until a choice is made between them.
An instance is the combination of:
A version number, initially empty and increasing 1, 2, 3… through successive baselines
A draft ID, either A if the item is not in a baseline or empty if the item is baselined. The values B, C … Z are used for alternative diagram and specification items in MBSE analysis or design models.
Structure of an Identity
The identity of an item is:
Item ID Instance ID
where:
Item ID
:
The collection of attributes that identify a specific item of a given item type
Instance ID
:
Which of possibly many instances of the item is being referred to
The different parts of item identities are:
Components of Item Identities
where:
Domain ID
:
Either E (for Essential) or I (for Implementation), the domain containing the item’s model
Model ID
:
The item’s model, either a numeric Model Unique ID (MUID) or a namespace showing the model in the domain’s model hierarchy, such as: As Built.Prototype A.Architecture
Type
:
Either one of the 26 diagram types that Cradle supports such as DFD, eFFBD, UCD, PAD and so on, or a specification type (process specification, environment terminator or module specification) or a user-defined item type such as PRODUCT REQ, SBS or VALIDATION
Stereotype
:
Only used by information in SysML models, the item’s stereotype, such as <<actor>>, <<block>>, <<constraint>>, <<message>>, <<package>> and so on
The item identity is fundamental in Cradle. All other methods of identifying or labelling items, including those described in this document, are secondary to these item identities.
PDUIDs
The above tables show that there are significant differences between the identities of item types. They make specifying and working with identities complex, and do not provide a single sequence of values to identify all items in a database.
These problems are solved by the Project Database Unique ID (PDUID), which:
Apply to all of the item types
Have the same format for all of these item types
Are in a single sequence for all items, for example:
A PDUID could reference a diagram in a model with namespace B.C (with an equivalent MUID)
The next PDUID could reference a TEST CASE system note item
The next PDUID could be a diagram in a namespace Y model (different MUID to the above diagram)
The next PDUID could reference a change request
The next PDUID could be a data definition in the model with namespace B.C
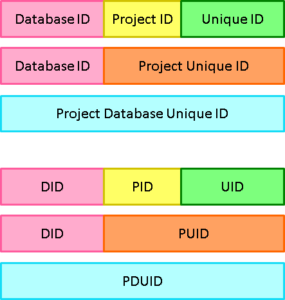
PDUID Structure
The format of a PDUID is:
Database IDProject IDUnique ID
where the Database ID and Project ID are as described earlier, and the Unique ID is a number 1, 2, 3… zero-padded to 10 digits. PDUIDs are 26 character strings with the structure:
Structure of PDUIDs
PDUID Examples
Some example PDUIDs:
0280A992E5SYSML_0000000022, in which:
0280A992E5 : is the DID, the Database ID
SYSML_ : is the PID, the Project ID
0000000022 : is the UID, the Unique ID
0280A992E5SYSML_0000000023
0280A992E5 : is the DID, the Database ID
SYSML_ : is the PID, the Project ID
0000000023 : is the UID, the Unique ID
0280A992E5SYSML_0000000024
0280A992E5SYSML_0000000025
Role of PDUID Components
As such, and given their constituent parts:
The Unique ID enables the PDUID to uniquely identify a database item
The Project ID enables the PDUID to uniquely identify an item across multiple databases
The Database ID enables the PDUID to uniquely identify an item between separate Cradle systems, even if everything else about information in the databases in these Cradle systems is the same
PDUIDs as Item Identities
A PDUID identifies an item, but not a specific instance of that item. This is deliberate. It is more convenient if the PDUIDs of all instances of an item are the same. Therefore, an alternative for the identity of an item is:
PDUID Instance ID
which identifies a specific instance of an item, where:
PDUID
:
Is the item’s PDUID as defined above that identifies an item
Instance ID
:
Which of possibly many instances of the item is being referred to, with the same meaning as above
PDUID Item Identity Examples
As examples, in the example database SYSM:
There is a use case diagram Automobile Use Case Diagram whose identity is:
Domain ID: I
Namespace: SysML-Automobile, which has MUID 100
Type: uc, meaning a SysML use case diagram
Stereotype: use case
Number: uc-1
Version:
Draft: A
which has been assigned the PDUID 0280A992E5SYSML_0000000035 so the item’s identity is also:
PDUID: 0280A992E5SYSML_0000000035
Version:
Draft: A
that can also be expressed as:
Database ID: 0280A992E5
Project ID: SYSML_, and hence PUID: SYSML_0000000035
Unique ID: 0000000035
In the same database there is also a TEST CASE item Keycode verification whose identity is:
Type: TEST CASE
Number: TC-20
Version:
Draft: A
which has been assigned the PDUID 0280A992E5SYSML_0000000024 so the item’s identity is also:
PDUID: 0280A992E5SYSML_0000000024
Version:
Draft: A
that can also be expressed as:
Database ID: 0280A992E5
Project ID: SYSML_, and hence PUID: SYSML_0000000024
Unique ID: 0000000024
Version:
Draft: A
PUIDs
Project Unique ID (PUID) is the name given to the PDUID without its Database ID (DID). In other words, PUIDs are a means to identify pieces of information in a single database.
PDUID Lookup
Every Cradle database contains a table that is used to check if a PDUID has been used and to convert between item identities and PDUIDs. This table is empty when a database is first created. The table is not part of the information in Cradle export files. Rather, the table’s contents are created when items are created in the database, either by an operation in the database such as creating or copying items, or reordering a hierarchy of items, or by importing information into the database from an external file.
This table is used to:
Check if a PDUID has been used
Find the PDUID for a given item identity
Find the item identity for a given PDUID
Find the next UID to be used
Entries in the table are marked deleted when the last instance of the corresponding database item is deleted.
Selective Reuse of PDUIDs
PDUIDs are never reused for different pieces of information, but they are reused for the same piece of information. This means that if a piece of information is deleted, its entry in the PDUID table is marked deleted, but the entry remains in the table. If that piece of information is ever recreated, then the PDUID table entry will be found, marked active, and the PDUID recorded in the table entry will be applied to the piece of information.
If items are auto-numbered, then the items’ identities are never reused and so PDUIDs are never reused.
For items that are not auto-numbered, or do not support auto-numbering (such as diagram, specification or data definition items in models), then PDUIDs can be reused. PDUIDs can also be reused when information is imported, and previously-deleted items are found in the PDUID table and their PDUIDs reused. This can be over-ridden on import as will be discussed later.
Example Scenario
As an example, consider the scenario:
Create item r1, the assigned PDUID is: 020A3857A3FRED__0000000001
Create item r2, the assigned PDUID is: 020A3857A3FRED__0000000002
Delete item r1
Create item r3, the assigned PDUID is 020A3857A3FRED__0000000003. Note that the UID in this PDUID is not 1 (which is now available since r1 was deleted), it is 3, because new PDUIDs always use the next UID value.
Create item r4, the assigned PDUID is: 020A3857A3FRED__0000000004
Create item r1, the assigned PDUID is: 020A3857A3FRED__0000000001 because the original PDUID table entry for r1 has been found and marked active and its PDUID has been reused so that the new item r1 is assigned the same PDUID as the original item r1.
Reuse of PDUIDs on Import
The reuse of PDUIDs is the correct approach as it ensures that a given item always has the same identity, regardless of what happens during the life of a project.
If, for whatever reason, this is not the behaviour that you want, then use auto-numbered items so that every item will be guaranteed to have a new identity and hence guaranteed to also have a new PDUID. Since auto-numbering makes the reuse of item identities impossible; auto-numbering also ensures that it is impossible to reuse PDUIDs.
Model Based Systems Engineering across the Systems Lifecycle
Complete Application Lifecycle Management (ALM) and Model-Based Systems Engineering (MBSE) solution for the entire project lifecycle, fully user-definable and applicable to all agile and phase based processes.
Supports the full systems development lifecycle at system, subsystem and lower levels
Integrates in one product features normally spread across separate tools from different vendors
Completely user-definable and user-extensible with point-and-click UIs
Manage any information, including requirements, models, risks, interfaces, tests and verifications
Scalable to millions of items of information
Full traceability of data from external sources and version management of source documents
Full traceability and coverage analyses
User-definable views of data including tables, trees, documents, matrices, diagrams and graphs
User-defined metrics and management dashboards
Cradle-SE Desktop is a complete solution to manage and trace all the data for your agile and phase-based projects.
Capture and Track Information
Capture information from external documents and tools, and track changes in these sources. You can build new sets of requirements, analysis, architecture and design models, tests or verifications, and link them to the source data and to each other. Check the consistency and quality of this information, and prove the integrity of the models and other data with bi-directional coverage and traceability analyses.
Customers’ confidence can be raised with proof that your work satisfies its sources and constraints, and will meet their needs.
Easily track progress with metrics and KPIs and link to your WBS and actual progress to your project planning tools.
Create Databases and Information
Create any number of databases, each with a schema and multiple projects that contain any number of items of any number of user-defined item types. Each item has any number of attributes with up to 1TByte of data, held in Cradle, or referenced in files, URLs or other tools.
All items can be linked with user-defined types of cross reference. The links have attributes to justify, explain or parametise them. Links are direct and indirect, for full lifecycle traceability, impact and coverage analyses.
External documents can be loaded into hierarchies of items. Every item in Cradle is linked to its source in a document. Changes in new document versions are automatically found and the database updated. You can prove the integrity of all source data to your customers with a range of detailed coverage analyses of their documents.
Items can be linear, hierarchical and in many-to-many relationships. Items can be split, merged and reordered. All information can be shared and reused. Cradle can support product ranges, models, variants and builds, and generate comparative analyses between them as tables, pivot tables and matrices.
Create any number of analysis, process, architecture and design models using UML, SASD, IDEF, ADARTS, SysML and other notations. Group models in hierarchies and link all elements of all models to requirements, SBS, issues, test cases and all other information.
Track and View Information
Cradle tracks all edits to every requirement, test case, verification and all other information that you want it to hold. Edits can be reversed selectively or by group. Full or partial change logs are readily available.
You define how information is viewed and reported in any number of views, shown as nested tables, trees, matrices, pivot tables and as diagrams.
Manage Projects
Manage your projects with:
Metrics, user-defined calculations of items’ values
Bi-directional links to Project, including user task lists and actual progress reporting
Cradle is open. It supports many import/export formats, has several interface mechanisms to link to other tools, and connects to Microsoft Office components Word, Excel, PowerPoint, Visio and Project.
Cradle is simple to customise and use. You do not need to learn a scripting language or become a programmer to tailor it to your process. After every change to your schema, Cradle will automatically update collections of queries, views and other definitions that make you productive immediately.
Major Features
The major features are:
Cradle-SE Desktop Features
Supported Platforms
The supported platforms are:
Characteristics
The characteristics are:
Cradle-SE Desktop Characteristics
Cradle-SE Desktop is part of the Cradle product range. The full, multi-user, product is Cradle Enterprise.
Requirements Management across the Systems Lifecycle
Complete Application Lifecycle Management (ALM) and Requirements Management (RM) and documentation solution for the entire project lifecycle, fully user-definable and applicable to all agile and phase based processes.
Supports the full systems development lifecycle at system, subsystem and lower levels
Integrates in one product features normally spread across separate tools from different vendors
Completely user-definable and user-extensible with point-and-click UIs
Manage any information, including requirements, risks, interfaces, tests and verifications
Scalable to millions of items of information
Full traceability of data to source and generated documents with complete version management
Full traceability and coverage analyses
User-definable views of data including tables, trees, documents, matrices, diagrams and graphs
User-defined metrics and management dashboards
Cradle-RM Pro is a complete solution to manage, trace and document all the data for your agile and phase-based projects.
Capture and Track Information
Capture information from external documents and tools, and track changes in these sources. You can build new sets of requirements, functions, components, interfaces, tests or verifications, and link them to the source data and to each other. Check the quality and structure of this information, and prove the integrity of information with bi-directional coverage and traceability analyses.
Customers’ confidence can be raised with proof that your work satisfies its sources and constraints, and will meet their needs.
Easily track progress with metrics and KPIs and link to your WBS and actual progress to your project planning tools.
Create Databases and Information
Create any number of databases, each with a schema and multiple projects that contain any number of items of any number of user-defined item types. Each item has any number of attributes with up to 1TByte of data, held in Cradle, or referenced in files, URLs or other tools.
All items can be linked with user-defined types of cross reference. The links have attributes to justify, explain or parametise them. Links are direct and indirect, for full lifecycle traceability, impact and coverage analyses.
External documents can be loaded into hierarchies of items. Every item in Cradle is linked to its source in a document. Changes in new document versions are automatically found and the database updated. You can prove the integrity of all source data to your customers with a range of detailed coverage analyses of their documents.
Items can be linear, hierarchical and in many-to-many relationships. Items can be split, merged and reordered. All information can be shared and reused. Cradle can support product ranges, models, variants and builds, and generate comparative analyses between them as tables, pivot tables and matrices.
Track and View Information
Cradle tracks all edits to every requirement, test case, verification and all other information that you want it to hold. Edits can be reversed selectively or by group. Full or partial change logs are readily available.
You define how information is viewed and reported in any number of views, shown as nested tables, trees, matrices, pivot tables and as diagrams.
Generate versions of documents such as a URD, SRD, IRS, SDS and SSDS to match your or your client’s formats with user-defined templates and detailed traceability of which items were published in each document issue.
Manage Projects
Manage your projects with:
Metrics, user-defined calculations of items’ values
Bi-directional links to Project, including user task lists and actual progress reporting
Cradle is open. It supports many import/export formats, has several interface mechanisms to link to other tools, and connects to Microsoft Office components Word, Excel, PowerPoint, Visio and Project.
Cradle is simple to customise and use. You do not need to learn a scripting language or become a programmer to tailor it to your process. After every change to your schema, Cradle will automatically update collections of queries, views and other definitions that make you productive immediately.
Major Features
The major features are:
Cradle-RM Pro Features
Supported Platforms
The supported platforms are:
Characteristics
The characteristics are:
Cradle-RM Pro Characteristics
Cradle-RM Pro is part of the Cradle product range. The full, multi-user, product is Cradle Enterprise.