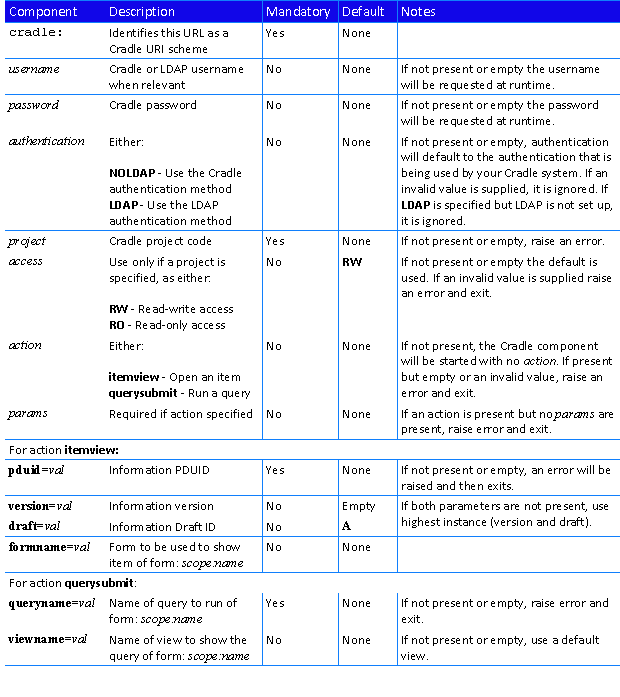
This is the fourth and last in a short series of posts that explain Project Database Unique IDs (PDUIDs). This post explains how PDUIDs can be controlled when importing information into Cradle.
Exchanging Information
The primary method of moving data into or out of Cradle databases is import/export. Regardless of the form of the data files used, there are some basic characteristics of import operations that affect the handling of PDUIDs and which can be controlled by the user when importing. These choices can be saved with other import options in an import format file. Such formats can be used for later imports, and specified for command-line based imports using the c_io utility. Using import format files is recommended as it ensures consistency between imports.
Default Behaviour
When importing information:
- Every item imported will have a PDUID when it is saved, even if the import data does not contain a PDUID
- The DID in the PDUID of all imported items will be set to the DID of the current Cradle system. For data that is being loaded from other Cradle systems, this means that the PDUIDs of the items in the original and imported databases will always be different. Even if their PUIDs are the same, their DIDs will be different.
- If an item being imported does not exist in the PDUID lookup table, then a new entry will be created in the table for the item. This new entry will have a PDUID. This PDUID will either be newly generated (the default), or if the import data contains a PDUID and the user has chosen to force the import of PDUIDs, then the PDUID from the import data will be used.
- If an item being imported exists in the PDUID lookup table and its table entry is marked deleted, then this table entry will be reinstated. If the user has specified to use the PDUID from the import file, the PDUID in the table entry will be replaced with the PDUID from the import file, else the table entry will be reinstated and the imported item will have the original PDUID from the lookup table.
- If an item being imported has a PDUID that is already used for a different item in the database, then the PDUID in the import file will not be used and the imported item’s PDUID will be replaced, regardless of any import options to the contrary
- All instances of an item have the same PDUID. Therefore, the PDUID of an item in the database will only be changed if all instances of the item can be changed. If there is any reason why all instances of an item cannot have their PDUIDs changed, then none of the instances will have their PDUIDs changed. As an example, if a user tries to import items with Overwrite set On and wants the PDUIDs in the import file to be used in the database, then the user must have RW access to all instances of the item in the database and the import data must update all of these instances.
Force Use of Existing PDUIDs
When importing data, you can choose to ignore any PDUIDs in the import/export file and instead keep the PDUIDs already in the database. To do this, de-select the checkbox Import PDUIDs from file (do not generate them)
This means that:
- If an item in the import data does not contain a PDUID, a PDUID will be generated for it as it is imported
- If an item in the import data does not exist in the database, then PDUIDs will be generated for them
- If the item in the import data does exist in the database, then the items will still have their original PDUIDs after the import and any PDUIDs in the import data will be ignored
Force Use of Import File PDUIDs
When importing data, you can choose to use PDUIDs in the import/export file and replace the PDUIDs already in the database. To do this, select the checkbox Import PDUIDs from file (do not generate them)
This means that:
- If the item in the import data does not contain PDUIDs, then PDUIDs will be generated for items as they are imported
- If the item in the import data does not exist in the database, then the PDUID in the import data will be used provided that it does not already exist in the PDUID lookup table and if it does exist in the table then if that table entry is active then a PDUID will be generated and if the table entry is not active then the PDUID in the import data will be used and the table entry will be replaced
- If the item in the import data does exist in the database, then:
- If the PDUID in the import data does not already exist in the PDUID lookup table then:
- The PDUID in the import data will be used
- Else if the lookup table entry is active then:
- If the lookup table entry is for a different item then:
- A PDUID will be generated and the PDUID in the import data will not be used
- Else if the user has RW access to all instances of the item and all instances of the item are to be updated by the import then:
- The PDUID in the import data will be used
- Else
- The PDUID already in the lookup table entry and the database items will not be changed
- If the lookup table entry is for a different item then:
- Else the lookup table entry is inactive so:
- The PDUID in the import data will be used
- If the PDUID in the import data does not already exist in the PDUID lookup table then:
Force PID Change
Whenever an item in an import file is to be imported as a new item in a database (not overwriting an existing item) then the PDUID for that new item will either come from the import data (if it contains PDUIDs) or a new PDUID will be generated. The PID in such PDUIDs will be either PID of the current database, or you can force a specific PID.
This can be useful if, you want to distinguish the data being imported with a specific PID, but the import data does not have that PID. For example, if you are importing into a single database data from multiple other databases then you might want to force the PIDs in the PDUIDs of items imported from database “A” to have one value and for the PIDs in the PDUIDs of items imported from database “B” to have a different value.
If you did this then, for instance, the PDUID facilities in queries could be used to distinguish between these sets of imported data.